
使用YOLOv5训练模型
使用YOLOv5训练模型
本文基于Windows系统环境,进行YOLOv5的从零开始的教学,用于北京信息科技大学机魂融创联盟的教学培训工作。
一、查看当前设备是否安装了CUDA
(1)首先:win+R 输入cmd 进入命令行 (2)输入命令 nvcc -V
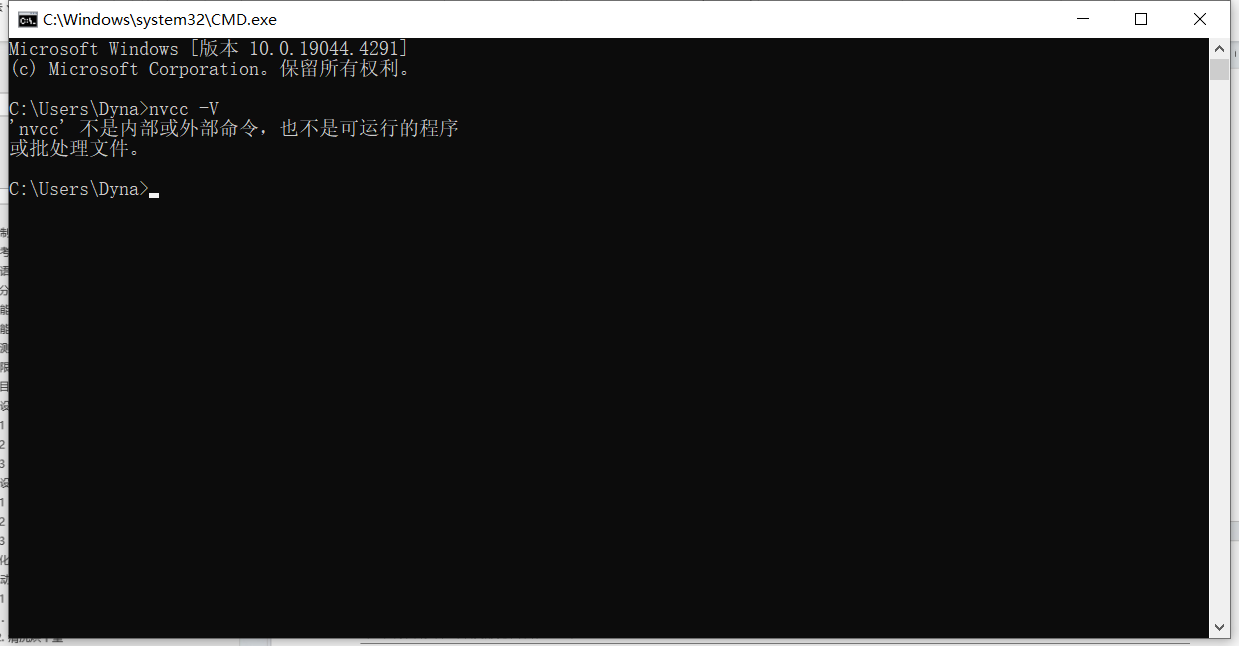
如果显示如下图所示的内容,说明设备没有安装CUDA,则按照下面的“2、安装CUDA”来进行。
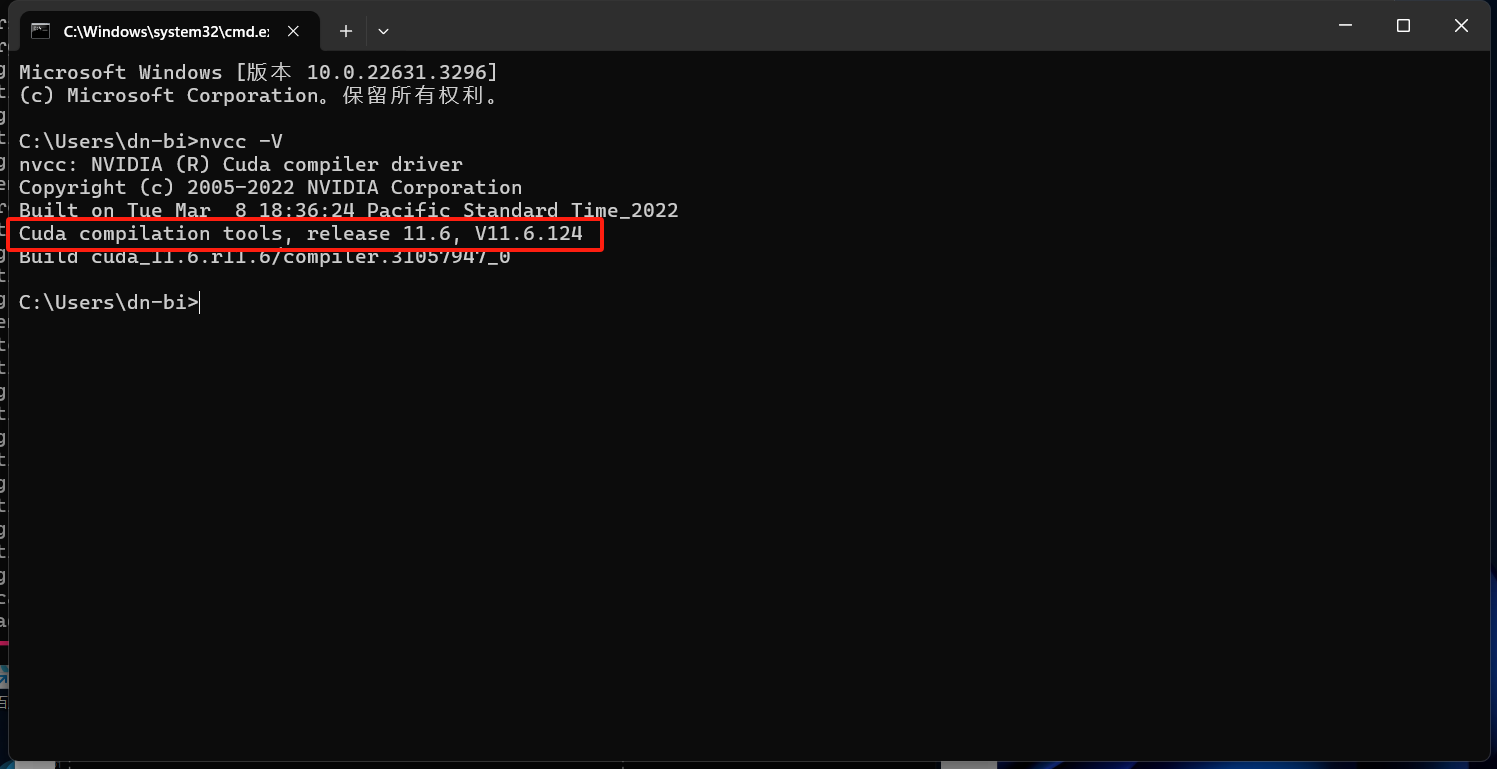
如果显示如下图所示的内容,说明设备已经安装CUDA,版本号在红框内,我这里为11.6,接下来
按照下面的“安装PyTorch”来进行。
二、安装CUDA
1.查看当前设备的显卡支持的CUDA版本
(1)首先:win+R 输入cmd 进入命令行 (2)输入命令 nvidia-smi
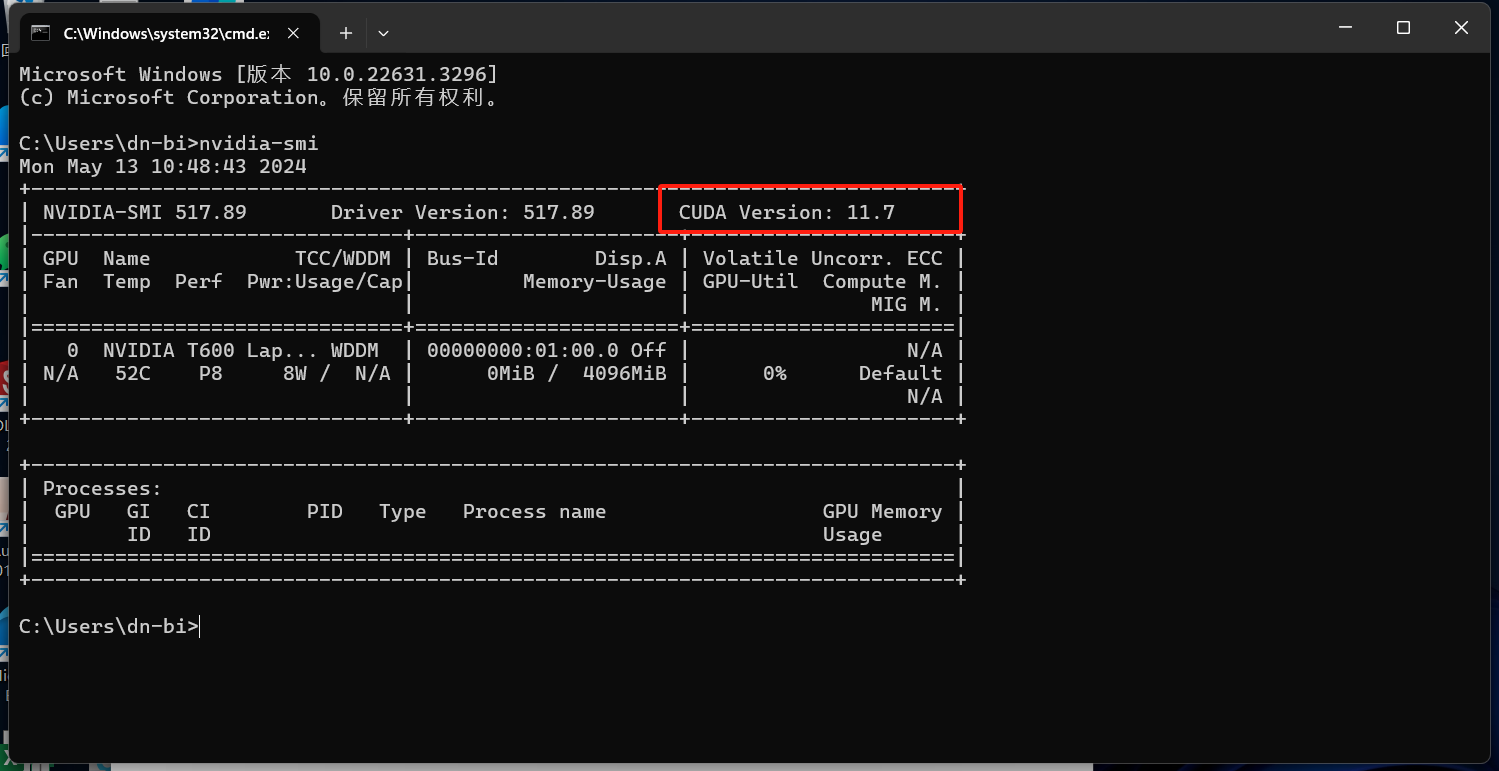
可见我这里支持的CUDA版本最高为11.7,一般使用同版本或低一个小版本,所以我这里使用的是11.6。
2.下载对应的CUDA版本
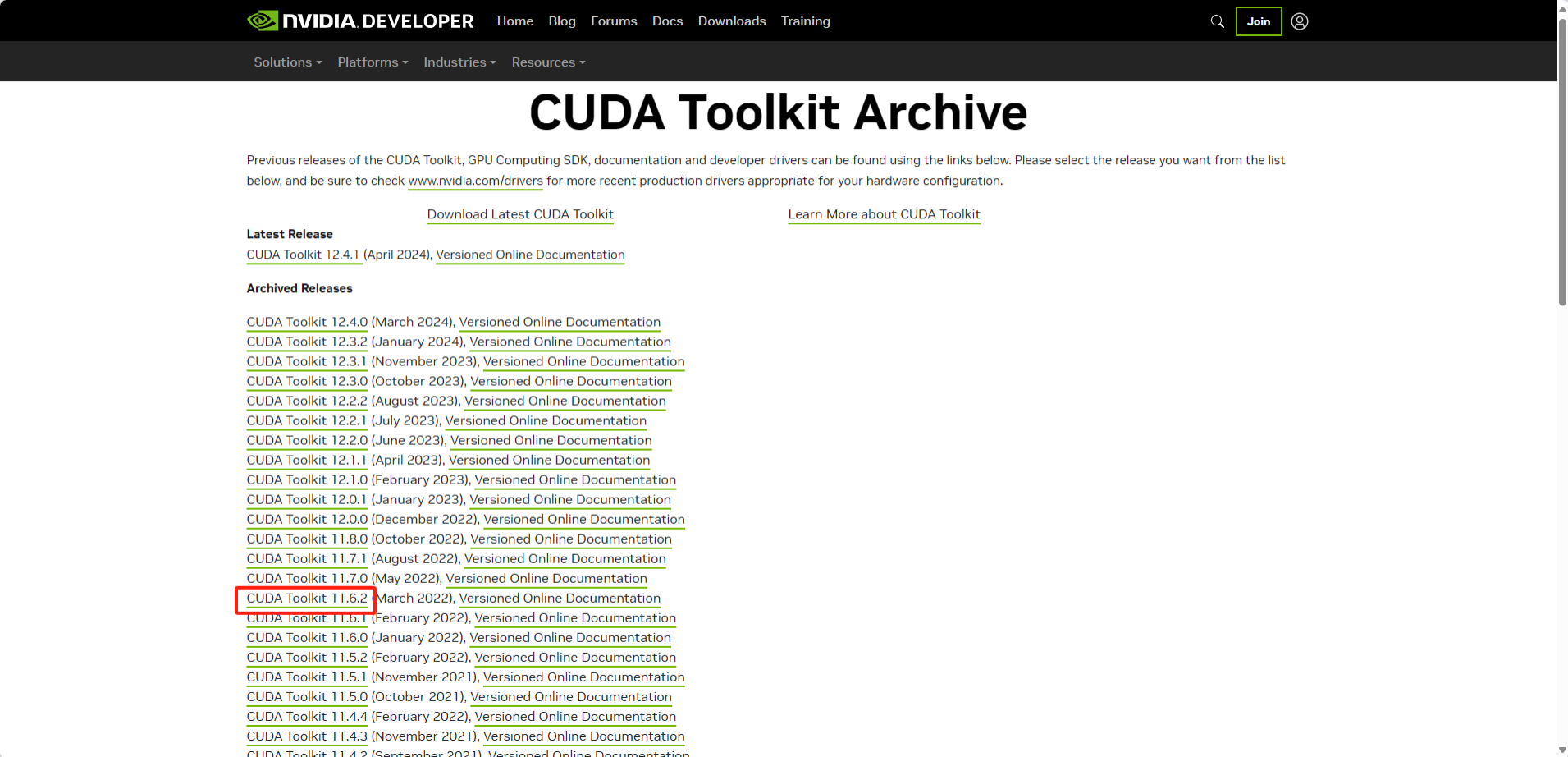
(1)打开CUDA下载页面:
CUDA Toolkit Archive | NVIDIA Developer
(2)在左侧找到对应的版本,点击版本名下载对应的版本
我这里下载11.6,所以点击11.6.2下载。
(3)下载完成后安装,安装时选择自定义,组件只保留CUDA即可。
安装位置我选择安装在默认位置,所以未修改。
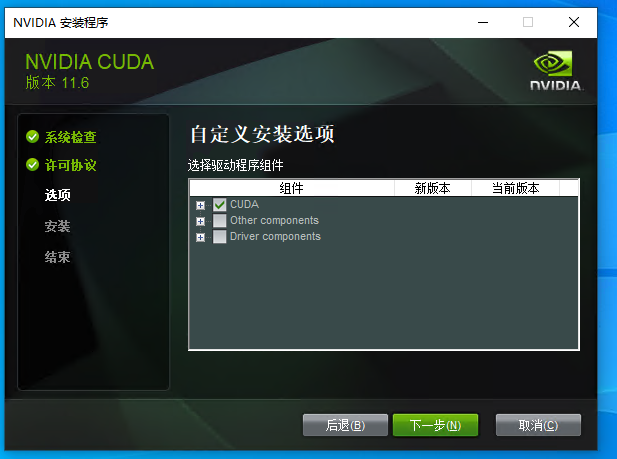
后面的步骤一直 下一步 即可
3.下载cuDNN
如果为近几年的显卡(一般按照这个来安装)
(1)打开cuDNN官网下载地址
https://developer.nvidia.com/cudnn-downloads
(2)选择对应平台(win11也选win10,不行再下载安装包)
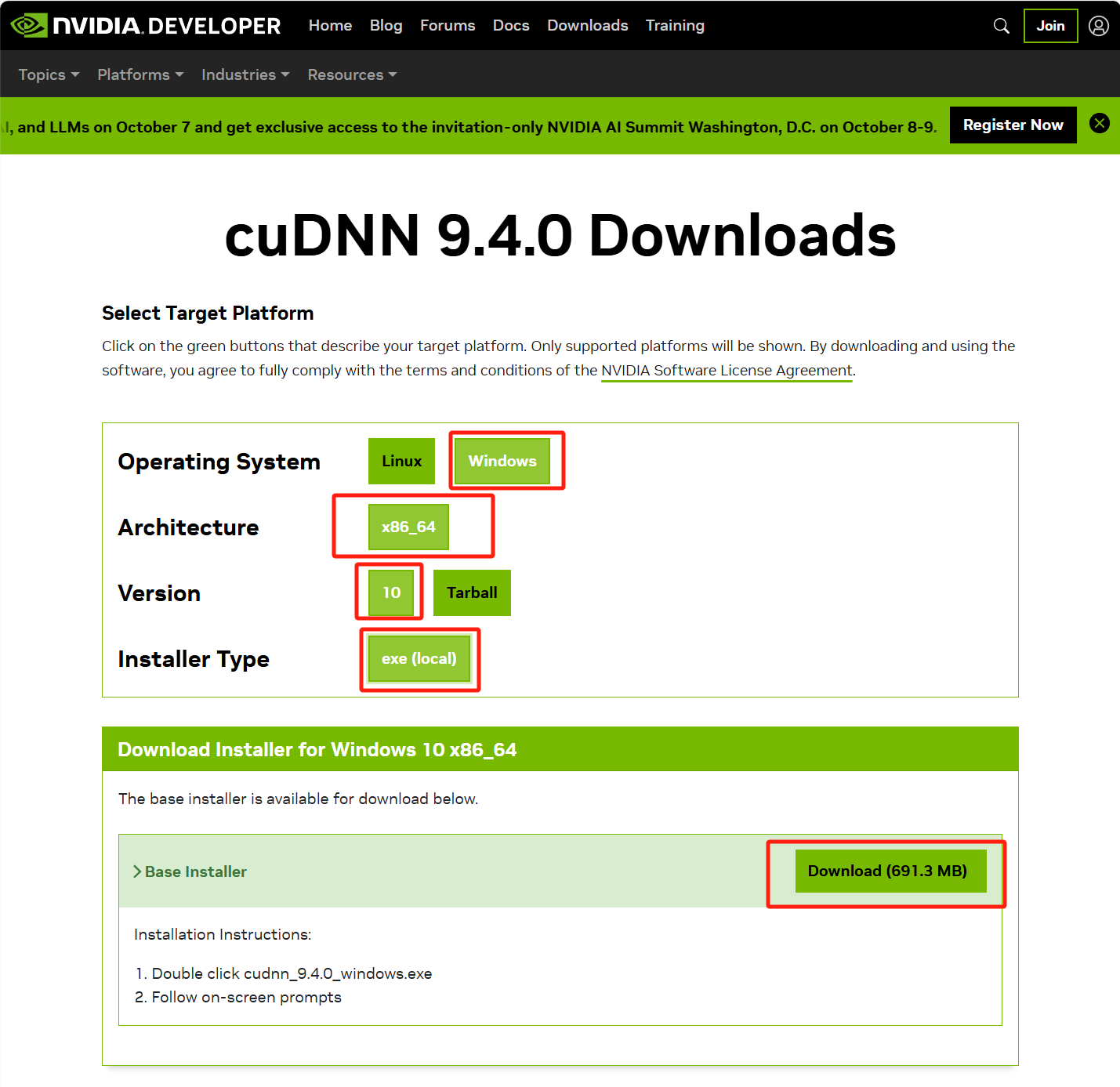
(3)下载完成后安装
依旧是一路下一步,然后选择自定义,选择自己需要的版本,安装。
如果为旧版本显卡
(1)打开cuDNN官网历史版本下载地址
cuDNN Archive | NVIDIA Developer
(2)选择对应CUDA版本的cuDNN版本

(3)点击下载

会要求登录,有账号的直接登录,没账号的注册一个,登录后会自动下载
下载完成后是一个zip(以windows为例)
根据以下参考资料完成后续配置:Cuda和cuDNN安装教程(超级详细)-CSDN博客
三、安装Python
如果已安装py3.9+可忽略,一般都可以,但是yolov5可能对py3.12+兼容性有限(后续可能进一步兼容了)
如果没安装,可以按照下面的流程来安装,对于训练yolov5而言更兼容一些
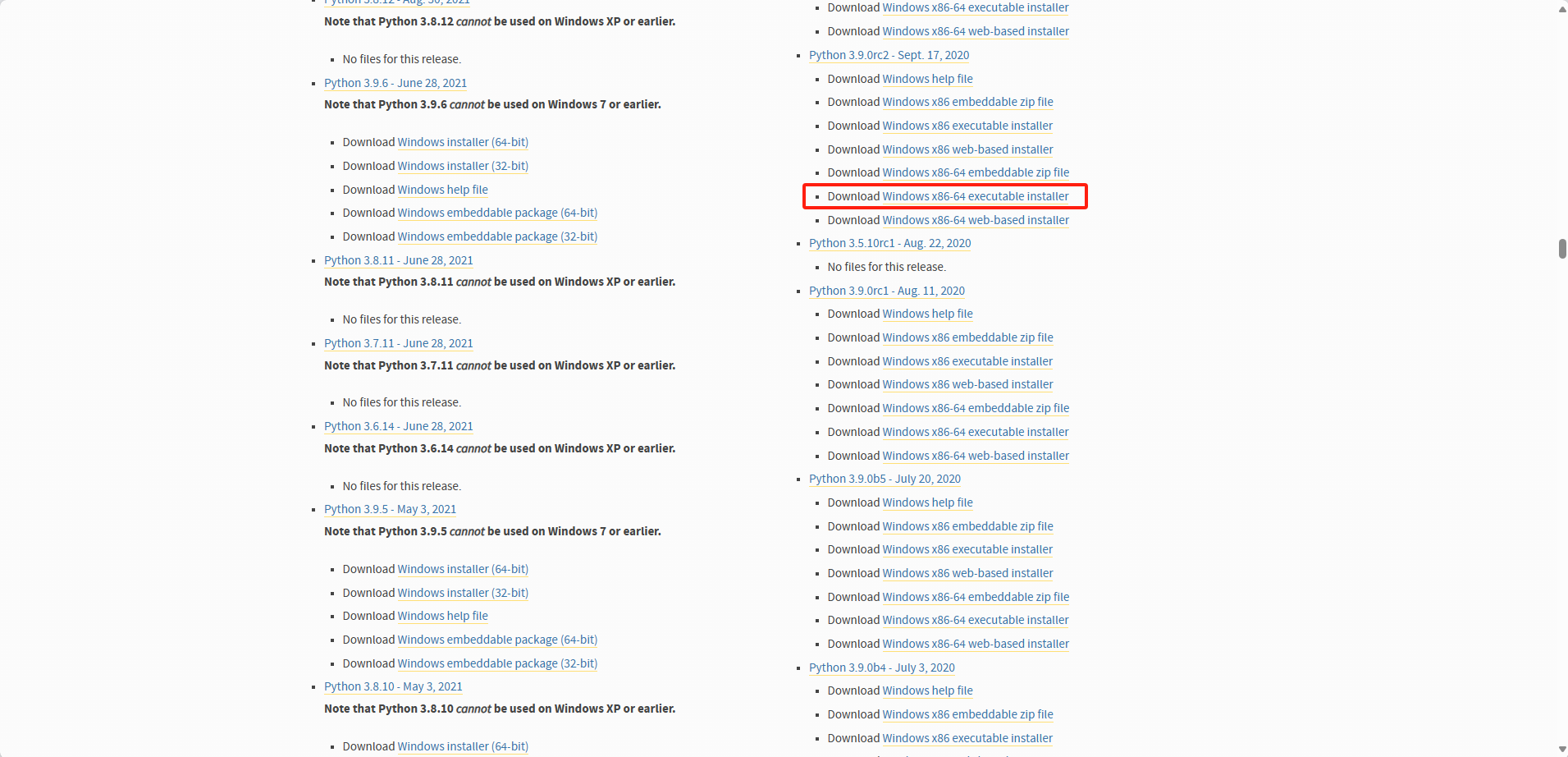
(1)打开PyTroch官网的pip库:download.pytorch.org/whl/torch/
(2)搜索对应的版本,比如我这里是11.6,则搜索cu116
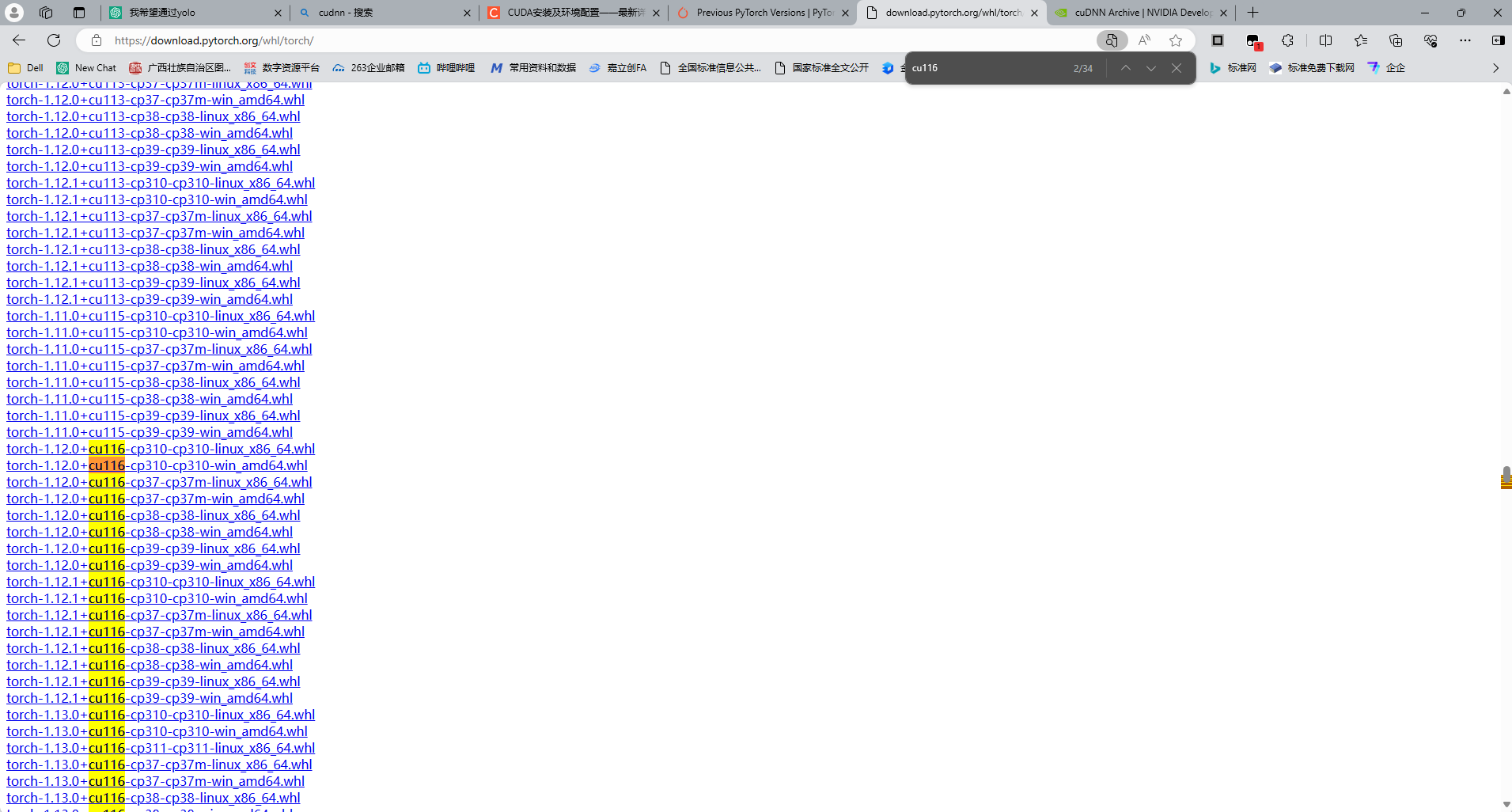
可以看到名字为 torch-版本号+cuda版本号-python版本号-python版本号-系统类型.whl 格式的内容,从图上可知,Windows环境下,CUDA 11.6支持python3.7到python3.10,不同CUDA版本兼容不一致,需根据实际情况来判断应该安装什么版本的python
(3)打开Python官网的旧版本下载网页:Python Releases for Windows | Python.org
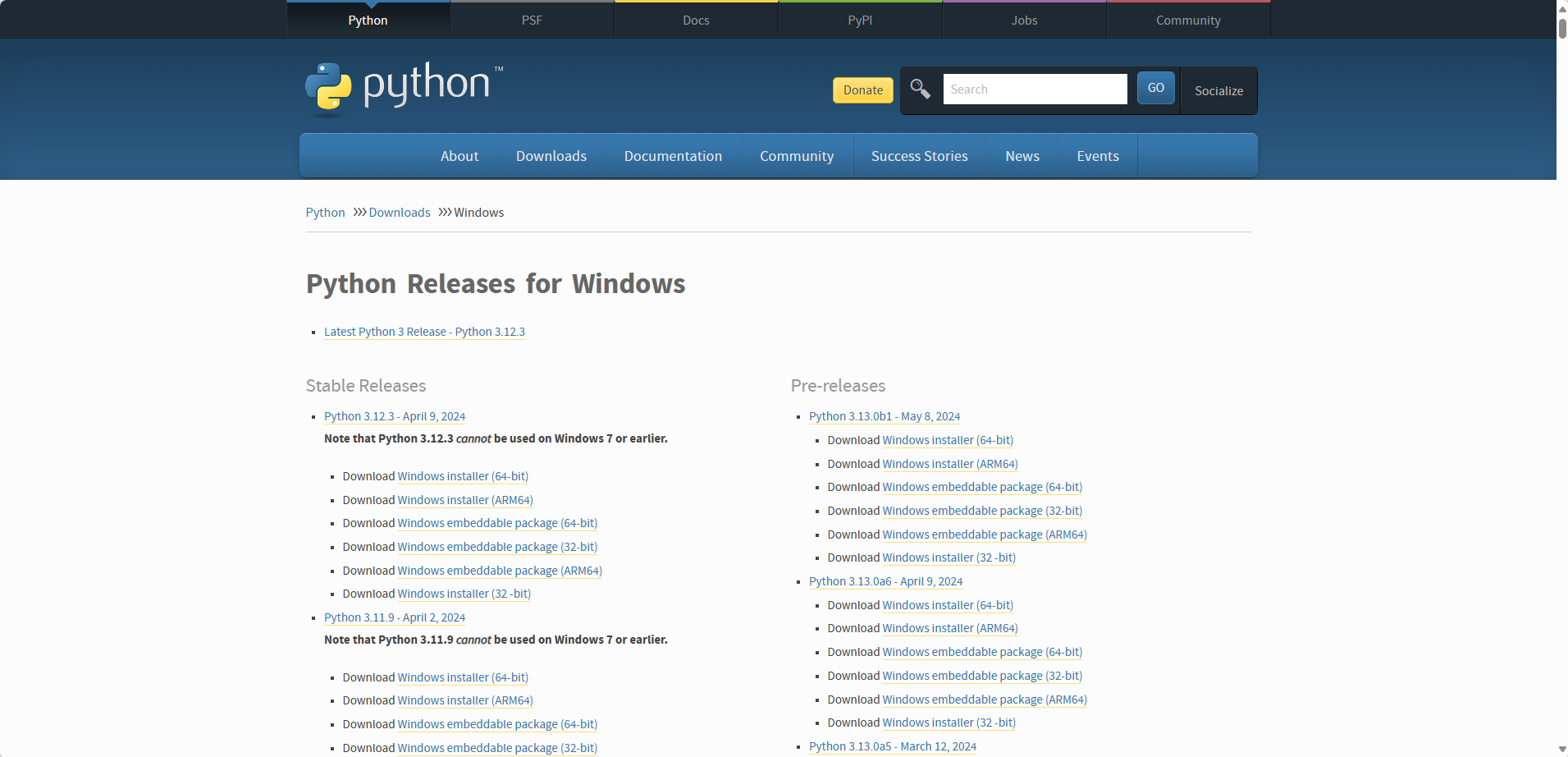
(5)下载对应版本Python,并安装。我这里下载的是Python 3.9 64位
四、安装PyTroch
1、如果为近几年的显卡
(1)如果CUDA版本为12.4及以上,则打开PyTorch
(2)选择如下内容
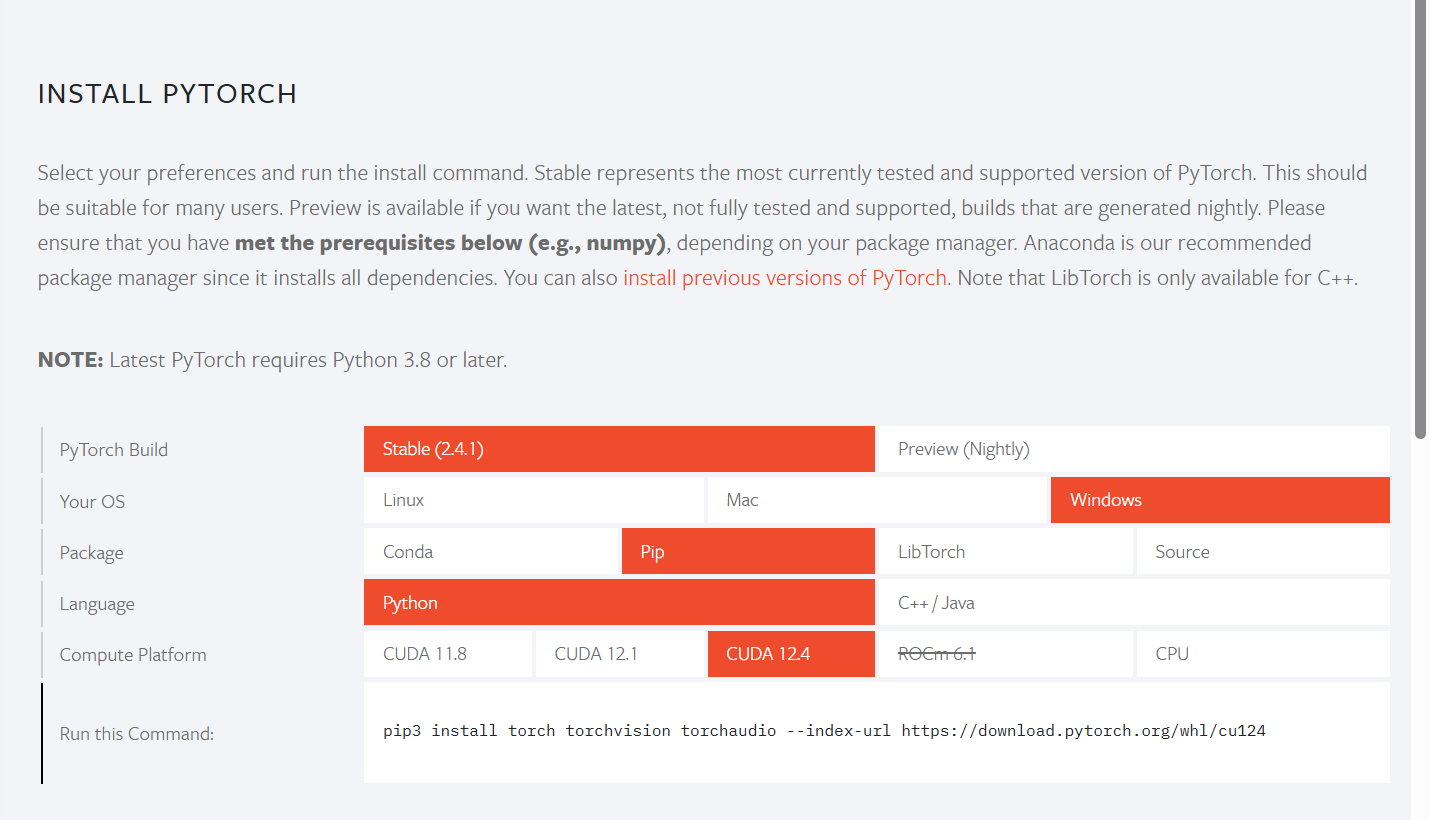
(3)复制pip链接,并粘贴到命令行中运行即可
2、如果为旧版本:
(1)打开PyTroch官网的版本库:Previous PyTorch Versions | PyTorch
(2)搜索对应的版本,比如我这里是11.6,则搜索cu116
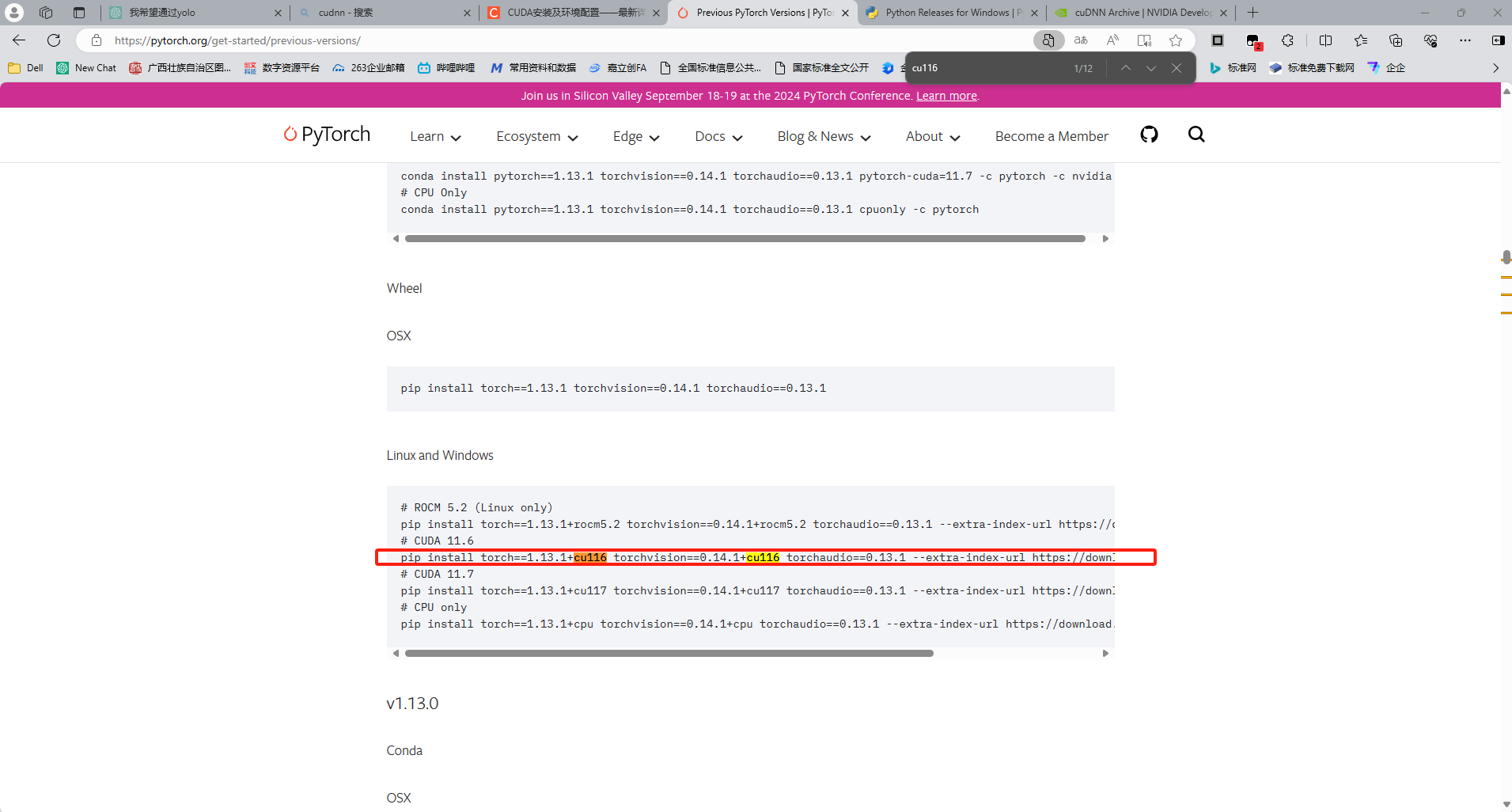
(3)复制对应的命令,并在命令行执行。
五、检查环境是否配置成功
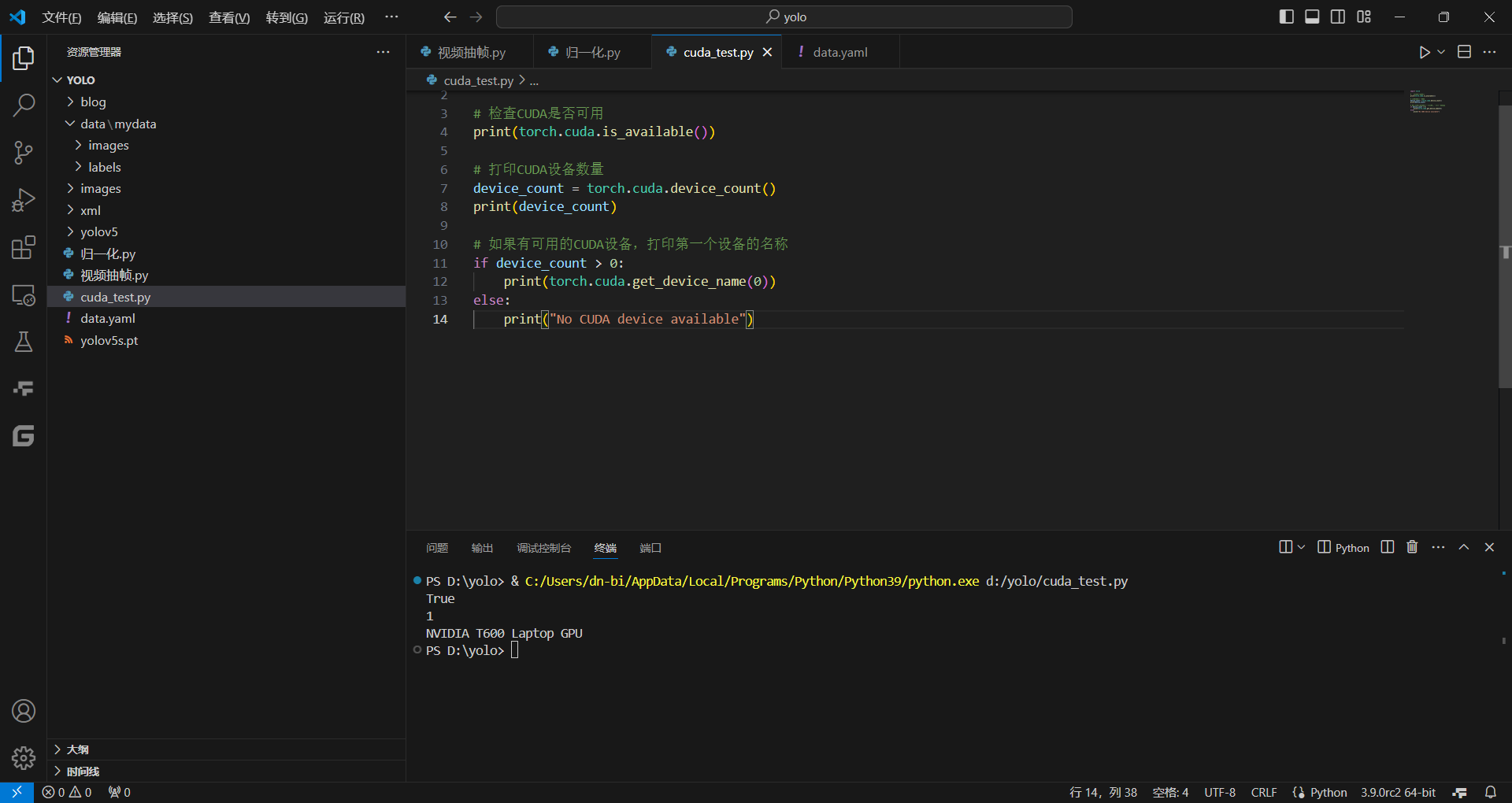
新建并运行以下python程序:
import torch
# 检查CUDA是否可用
print(torch.cuda.is_available())
# 打印CUDA设备数量
device_count = torch.cuda.device_count()
print(device_count)
# 如果有可用的CUDA设备,打印第一个设备的名称
if device_count > 0:
print(torch.cuda.get_device_name(0))
else:
print("No CUDA device available")如果显示"No CUDA device available"则说明没有安装成功,需要重新走流程。
如果终端显示类似下面的内容,则说明安装成功
六、下载YOLOv5模型
关于YOLOv5的代码详解可参考以下链接:YOLOv5源码逐行超详细注释与解读
注意:如果你使用的是机魂社已经配置好的环境,请直接跳到第七步,执行完第七步后执行第九步。如果想自己配环境,则继续按顺序执行。
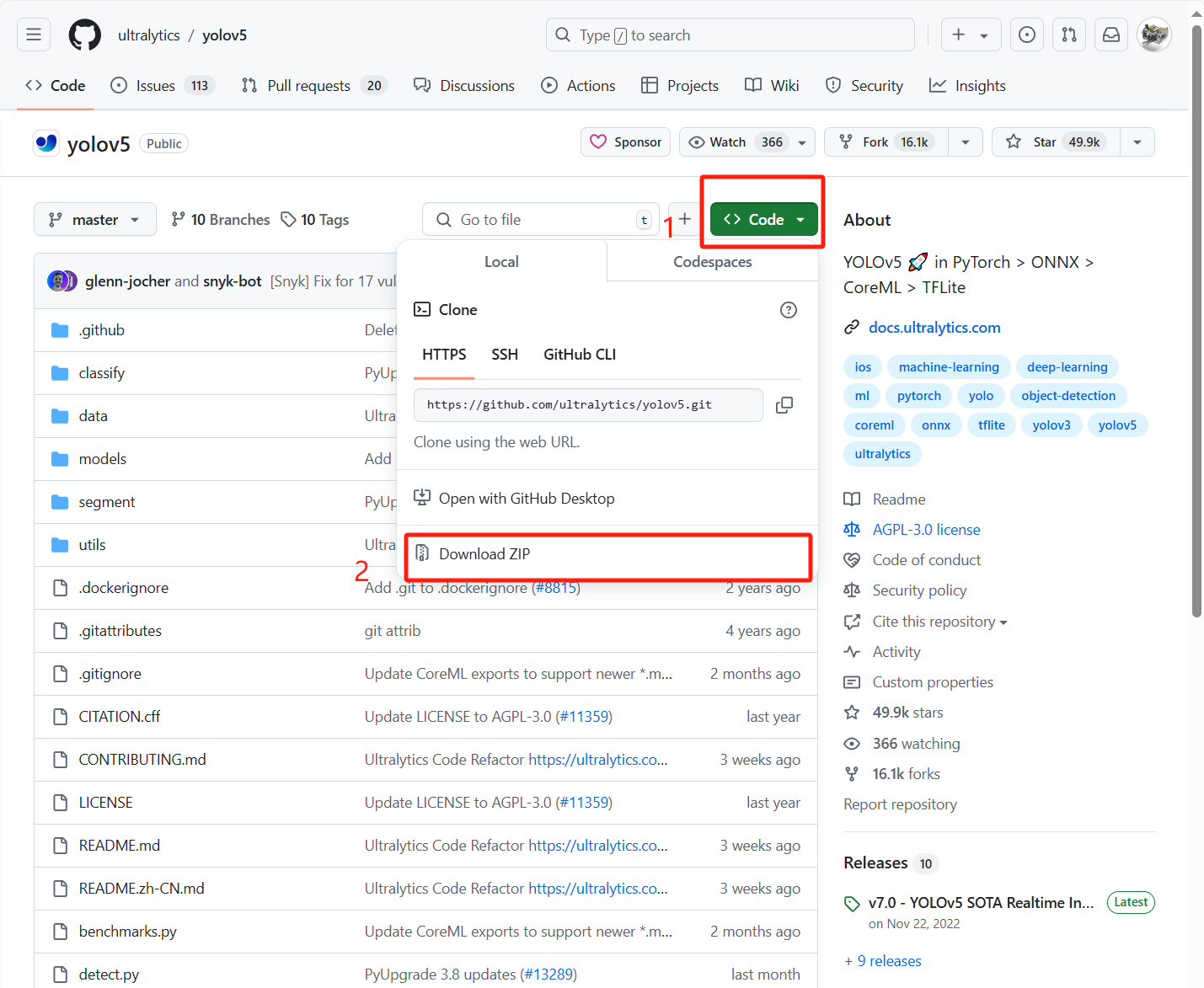
(1)打开YOLOv5的github地址:
ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite (github.com)
(2)按图中步骤下载代码
(3)解压到一个目录当中
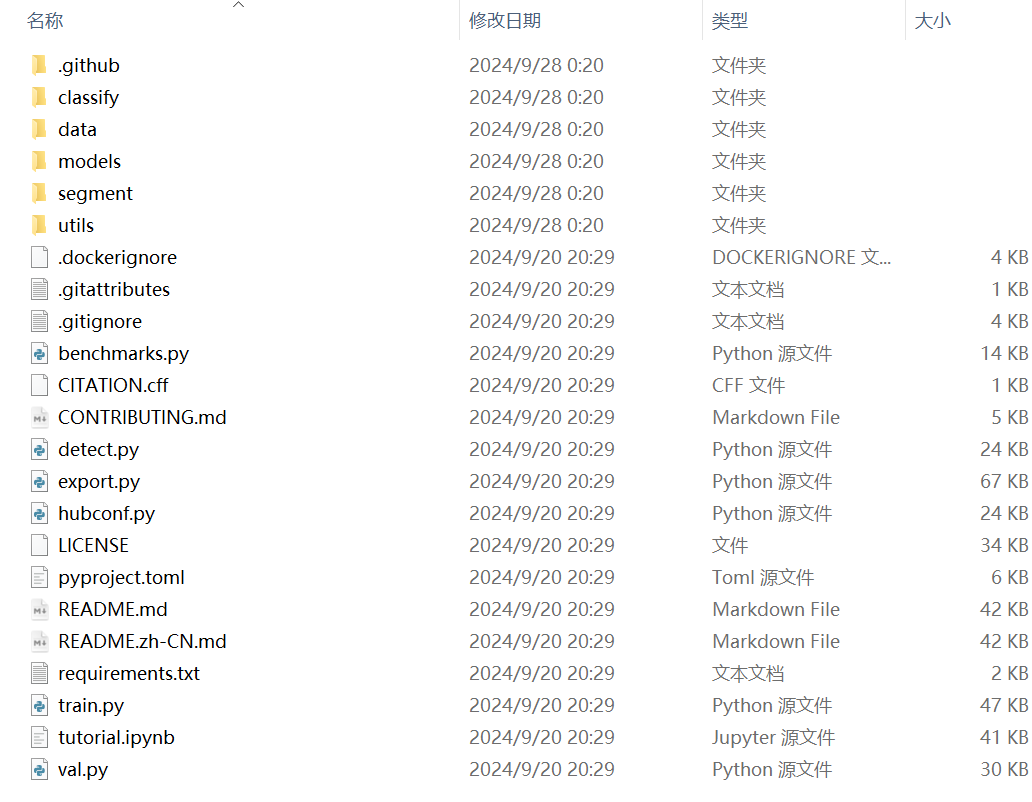
(4)打开目录(此目录以下称为YOLO目录或类似描述)
(5)(可选)将以下无关内容删掉(看着顺眼,没别的原因)
(6)下载预训练模型模型
在YOLOv5的github地址中可以看到如下的一个表格
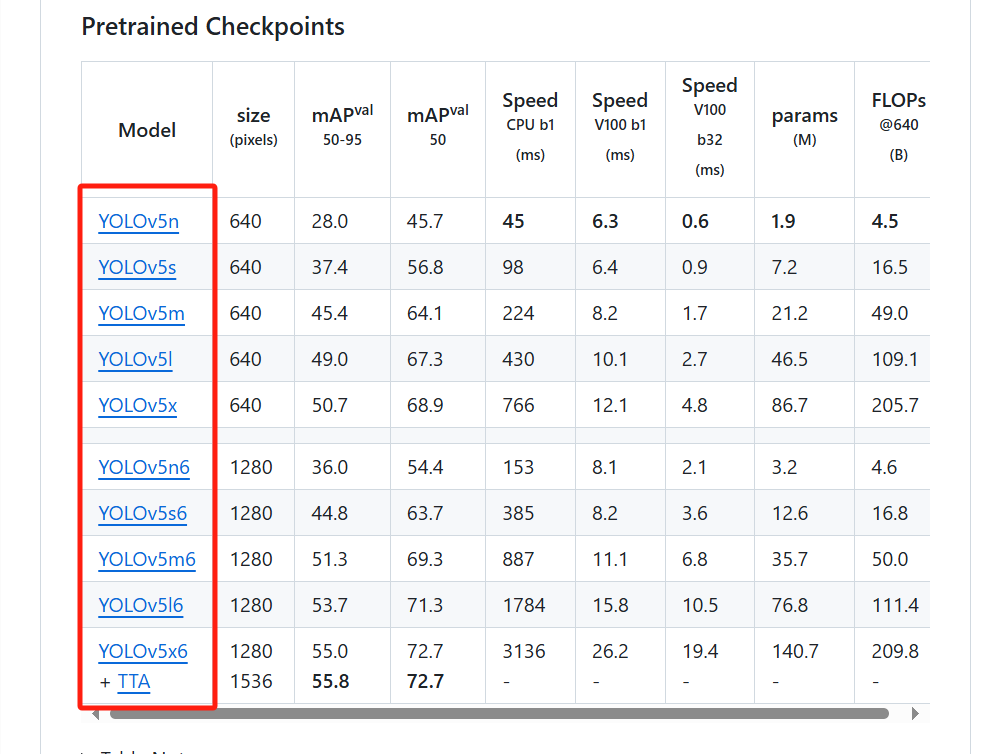
点击前方蓝色字可以下载对应的模型,前期学习使用YOLOv5n或YOLOv5s即可(根据自身显卡性能进行选择)。
下载完成后放置到yolo目录下的models文件夹内。
注意:如果你使用的是机魂社已经配置好的环境,models文件夹内已下载了YOLOv5n、YOLOv5s、YOLOv5m三个常用模型,无需再次下载
七、配置YOLOv5依赖
在yolo目录下打开命令行
输入以下语句进行环境配置和应用下载
pip install -r requirements.txt八、创建一个项目文件框架
注意:如果你使用的是机魂社已经配置好的文件环境,则下面的文件框架已经在你的文件夹内,可直接复制、修改使用。
1、创建文件框架
(1)在YOLO目录下新建一个文件夹,文件夹名字自拟,如:my_yolo_test(该文件夹后续简称项目文件夹或类似名称,同时也建议该文件夹名称和自己的训练项目有关,以示区分)
(2)在项目文件夹内新建以下文件夹:
train(训练集文件夹)
val(验证集文件夹)
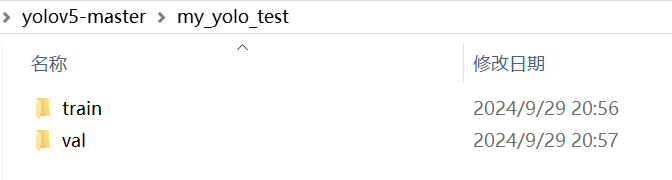
并在两个文件夹内分别建立下面两个文件夹
images(图片文件夹)
labels(标注文件夹)

(3)在项目文件夹内新建一个yaml文件,文件名自拟,如:my_yolo_test.yaml(建议与项目文件夹同名,以示区分)

文件内容如下:
train: ./my_yolo_test/train/images # 训练集图片文件夹路径
val: ./my_yolo_test/val/images # 验证集图片文件夹路径
nc: 1 # 类别数量,下面只有一个类别,所以写1
names: ['louyoudian'] # 类别名称列表,此处可自定义,如果有多个类别,则参考下面的样式
# names: ['category1', 'category2', 'category3'] # 假设有三个类别,将三个类别名称 依次 填入列表中注意:图中第5行的 “louyoudian” 与下面的9、准备训练集中设定的类别名称同步即可
九、准备数据集
1、准备数据集图片
将需要训练的图片分成两部份,一份放入train文件夹的images文件夹内,一份放入val文件夹的images文件夹内,二者比例一般介于7:3和8:2之间。
2、使用labelimg打标签
(1)在终端中输入以下语句进行labelimg的下载安装
pip install labelimg(2)安装完成后,使用命令labelimg运行labelimg程序。运行后效果如下:
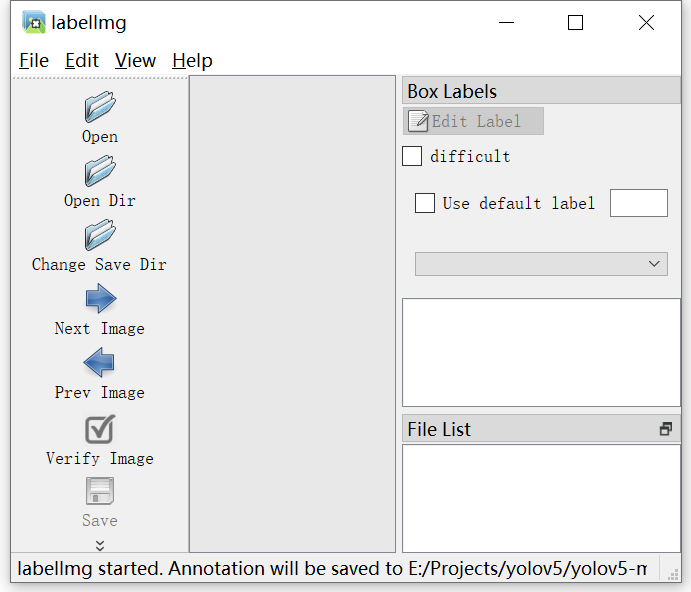
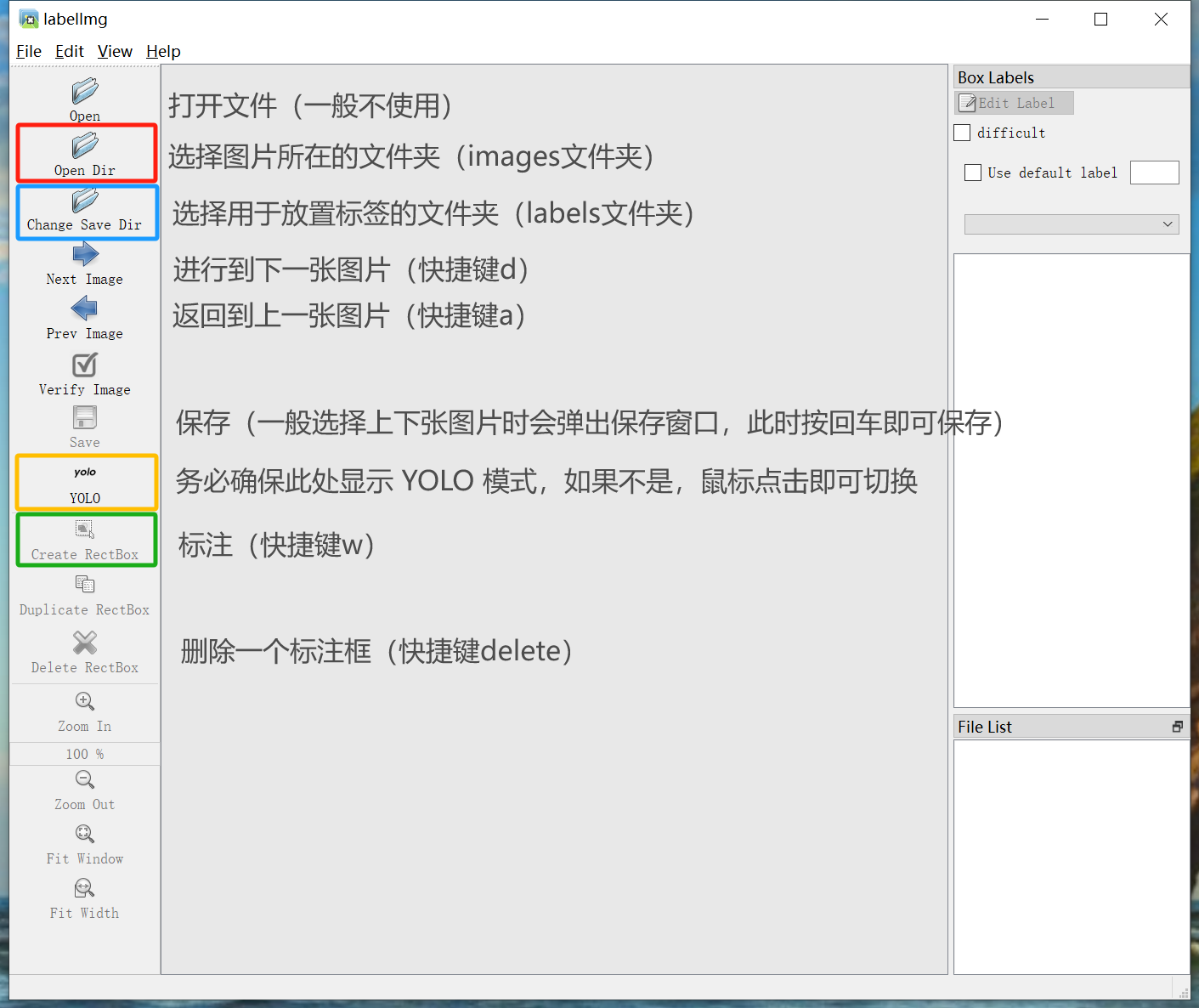
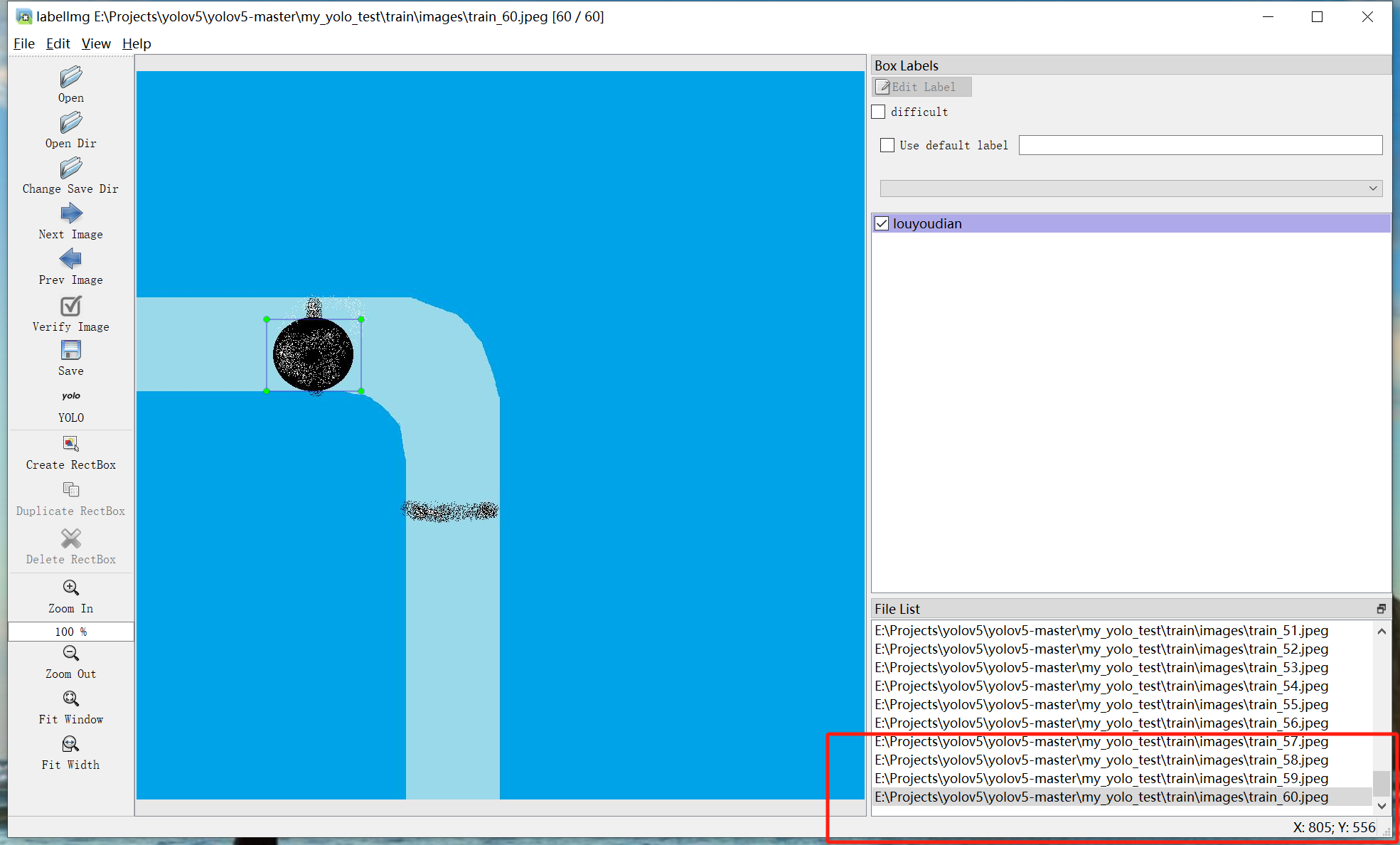
界面功能见图示。右下角可以拖拽调整大小,将其调整到舒适的大小:
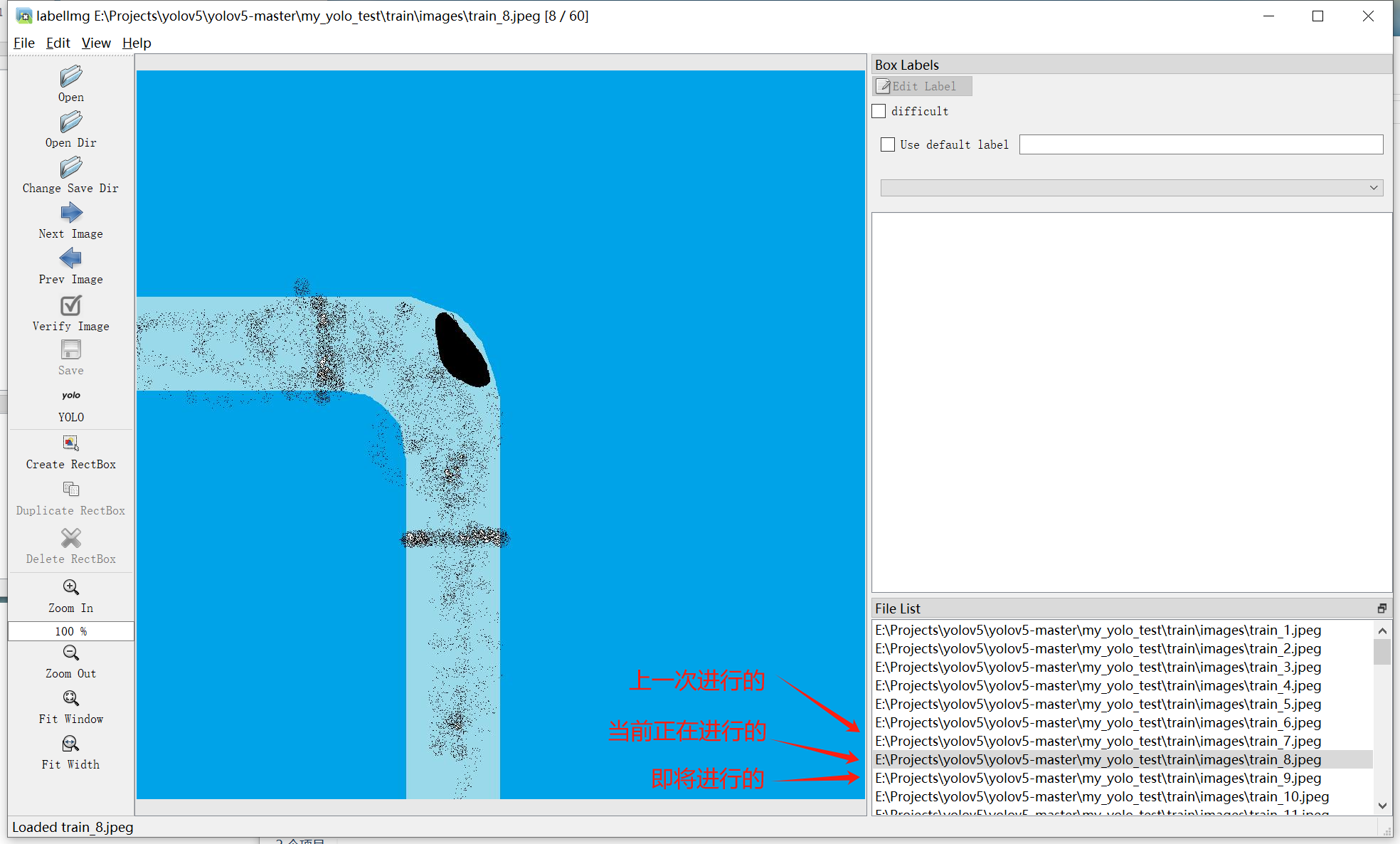
(3)打开文件夹(此处以训练集为例,my_yolo_test\train\images)
打开后会在中间显示图片:
(4)选择放置标注的文件夹(此处以训练集为例,my_yolo_test\train\labels)
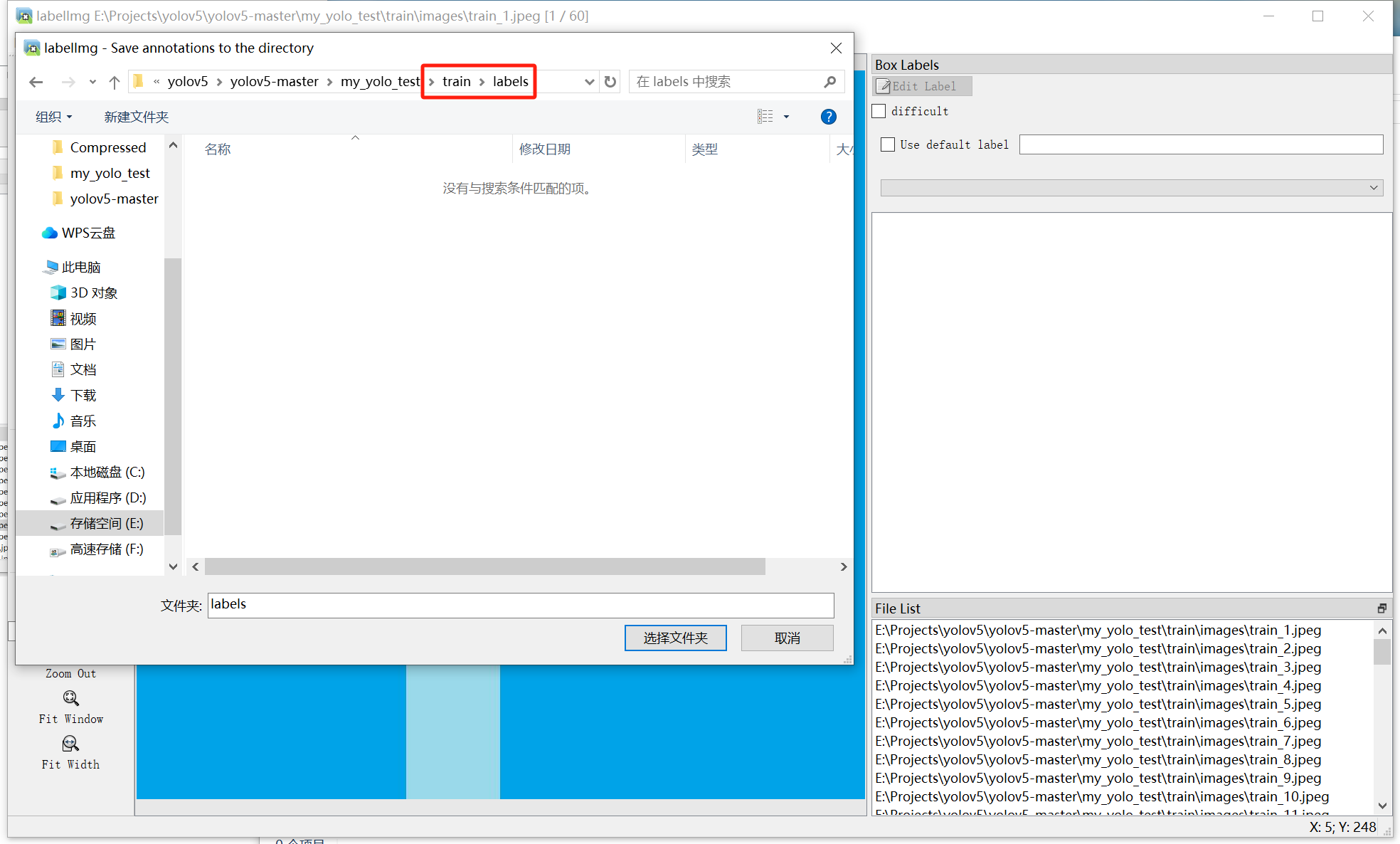
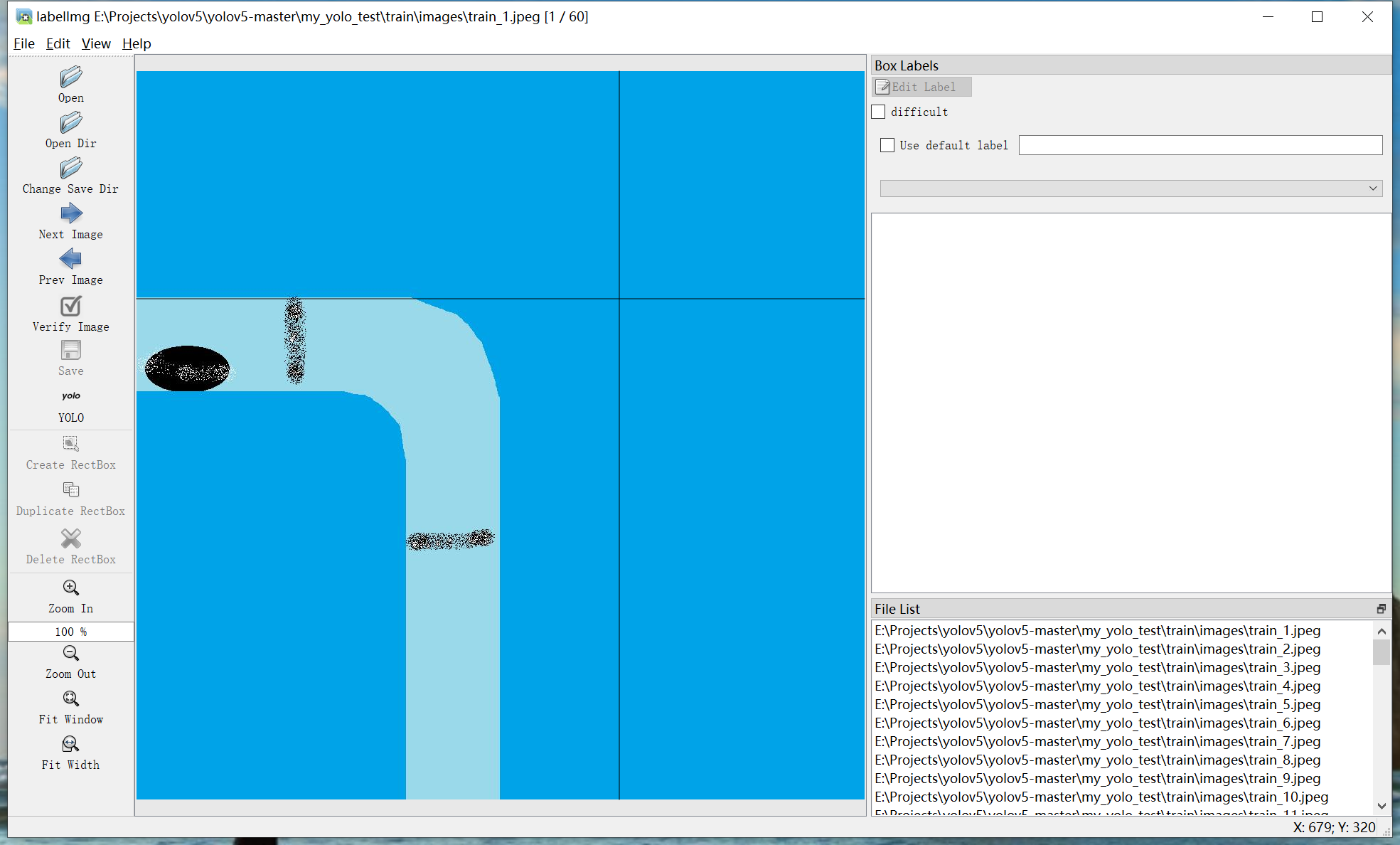
(5)开始标注
a.按下快捷键w,中间图片框会出现贯穿的十字型线条:
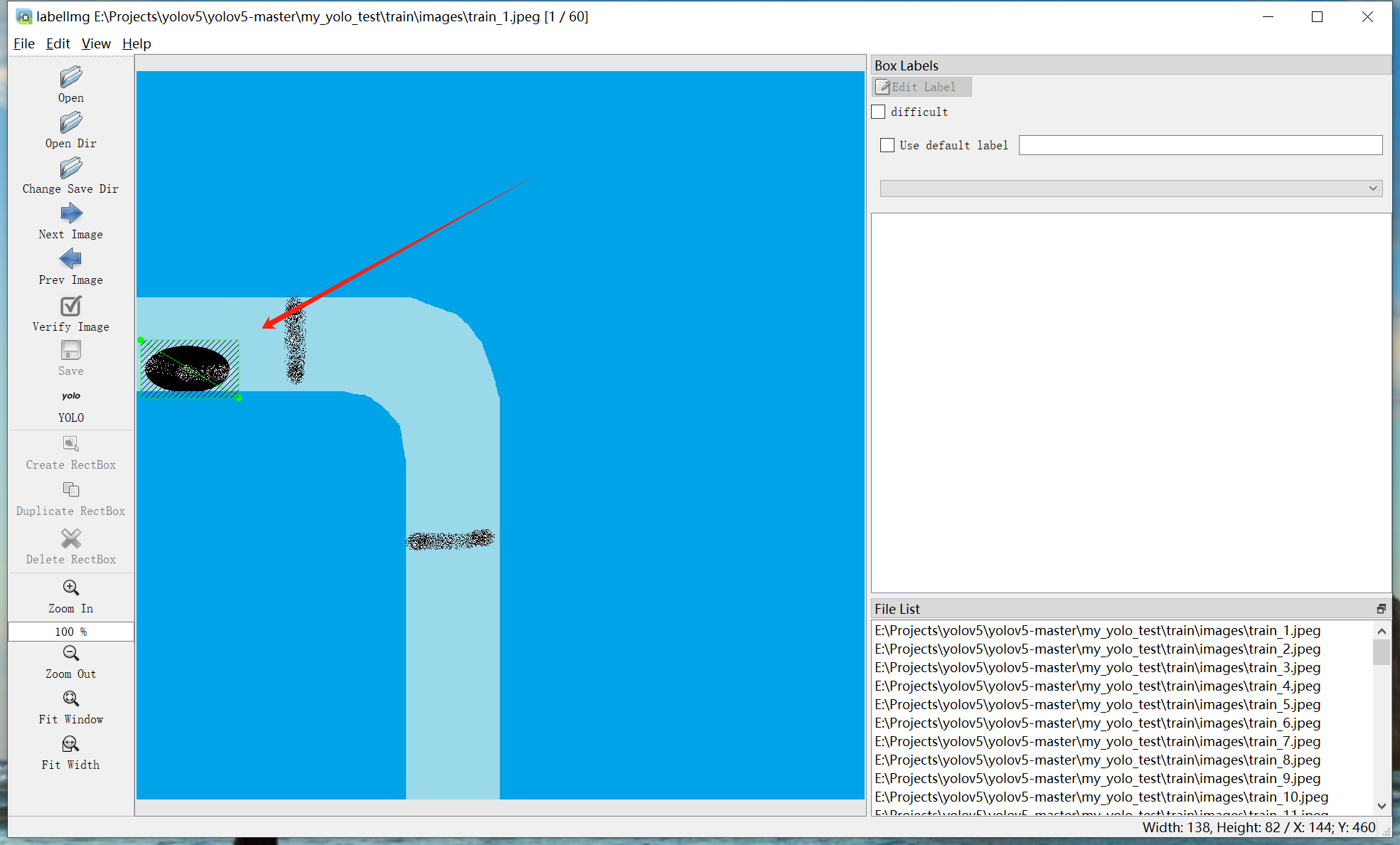
b.按下鼠标左键,从一角划到对角(例如从左上划到右下),可以看到,我希望标注的图像被绿色方框框起:
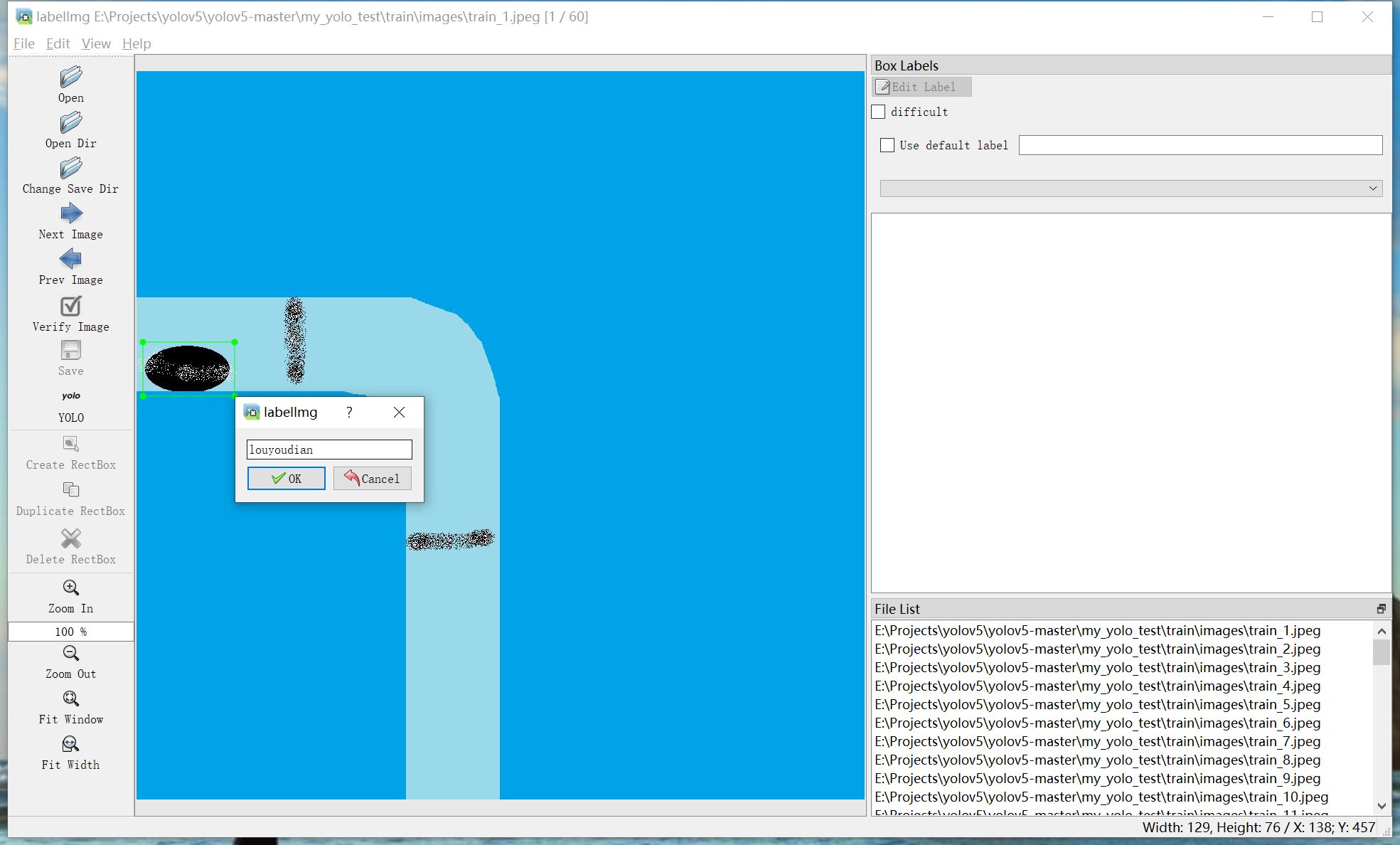
c.松开鼠标左键可以看到弹出命名弹窗,我这里训练的是漏油点识别,所以输入了“louyouidan”,根据具体情况自行命名。须为英文。
d.点击ok(快捷键:回车),可以看到右侧显示出了名称:
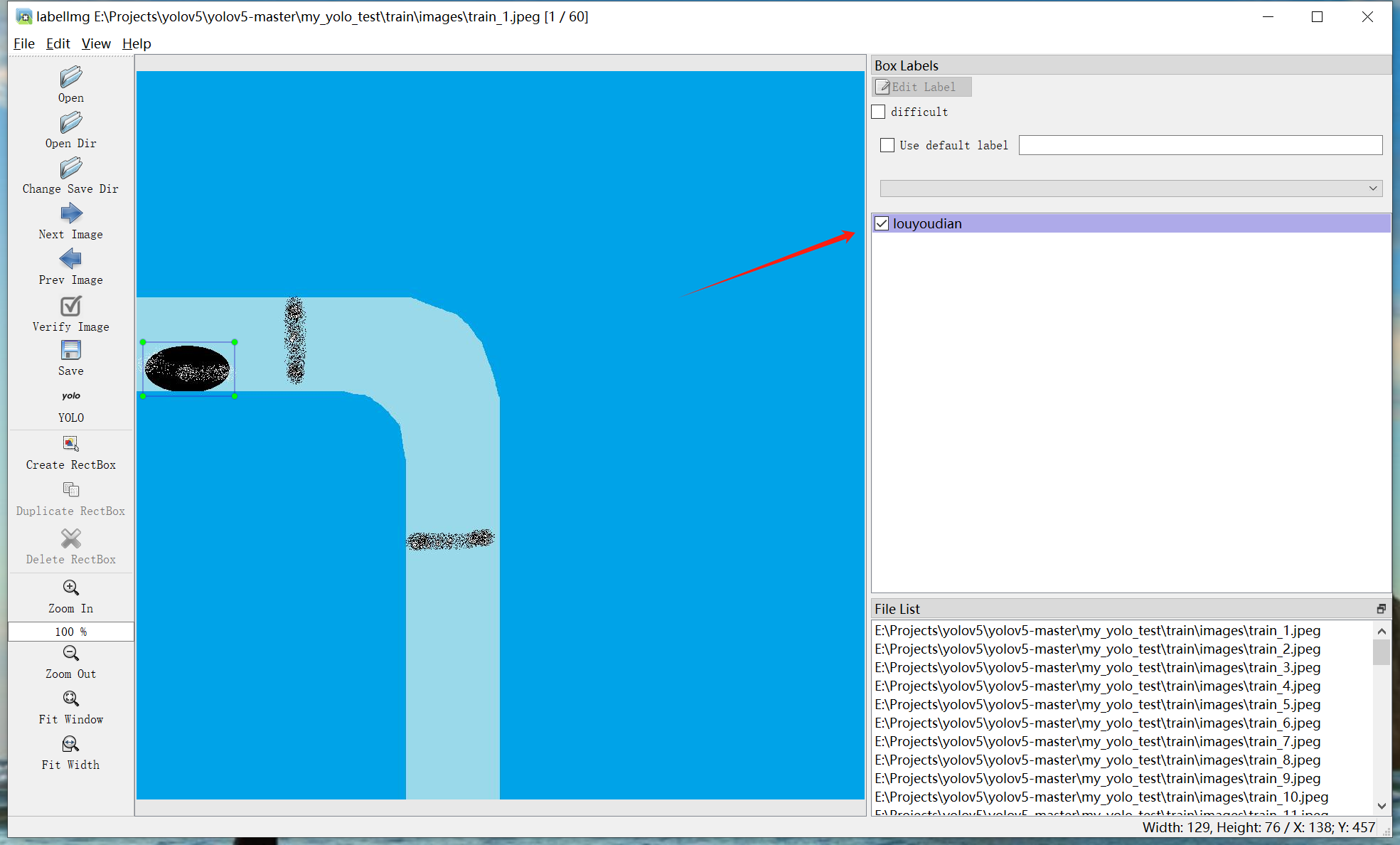
此时当类别已标注完成,如果图片中有多个漏油点,或需要标注其他类型,则从a开始重复至此步骤。
如果图片中全部内容已被标注完毕,则按下快捷键d,切换到下一张图片。
e.按下快捷键d,出现保存提示弹窗,按快捷键enter确定:
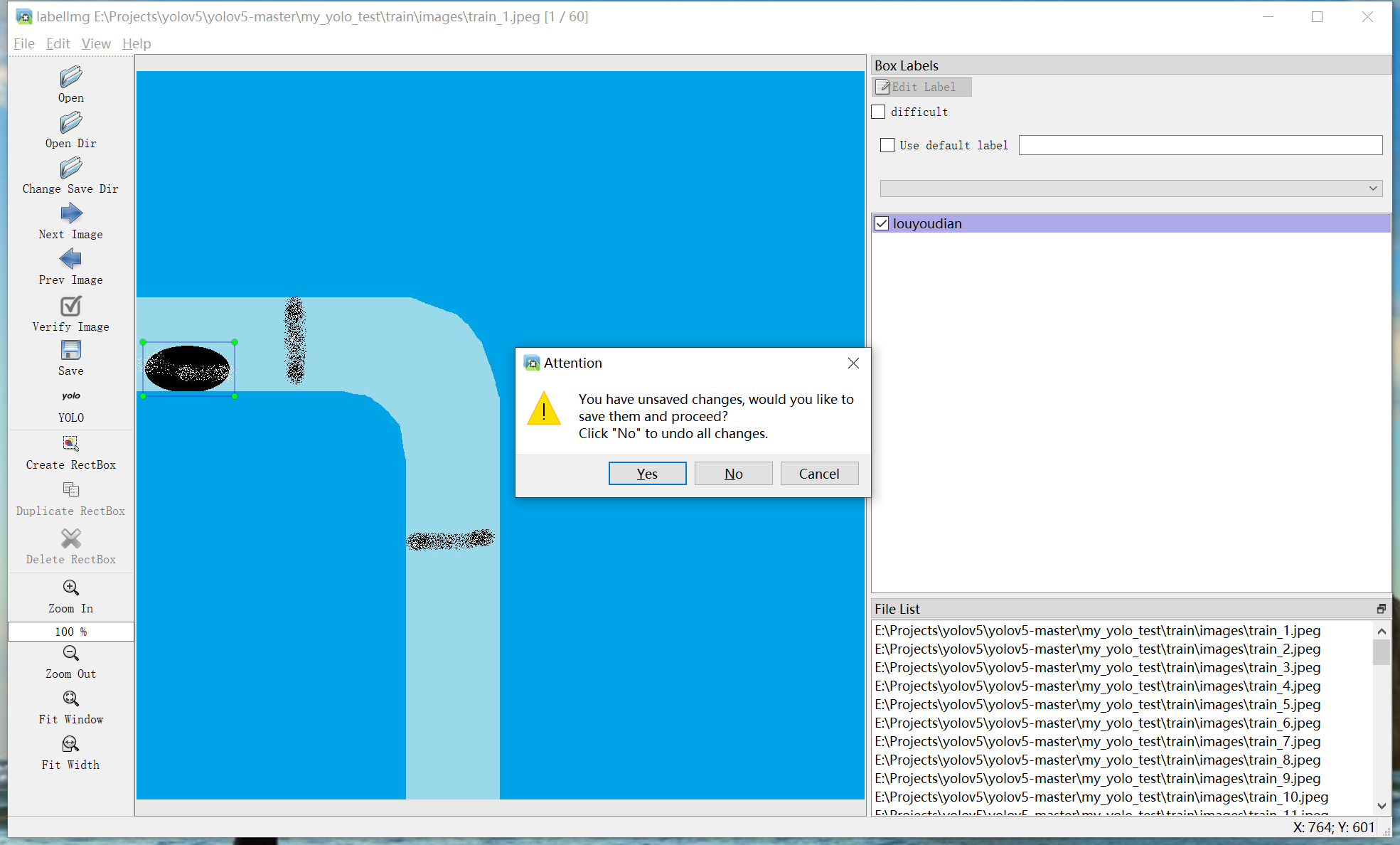
此时当前图片被标注完毕,并自动进入下一张图片:
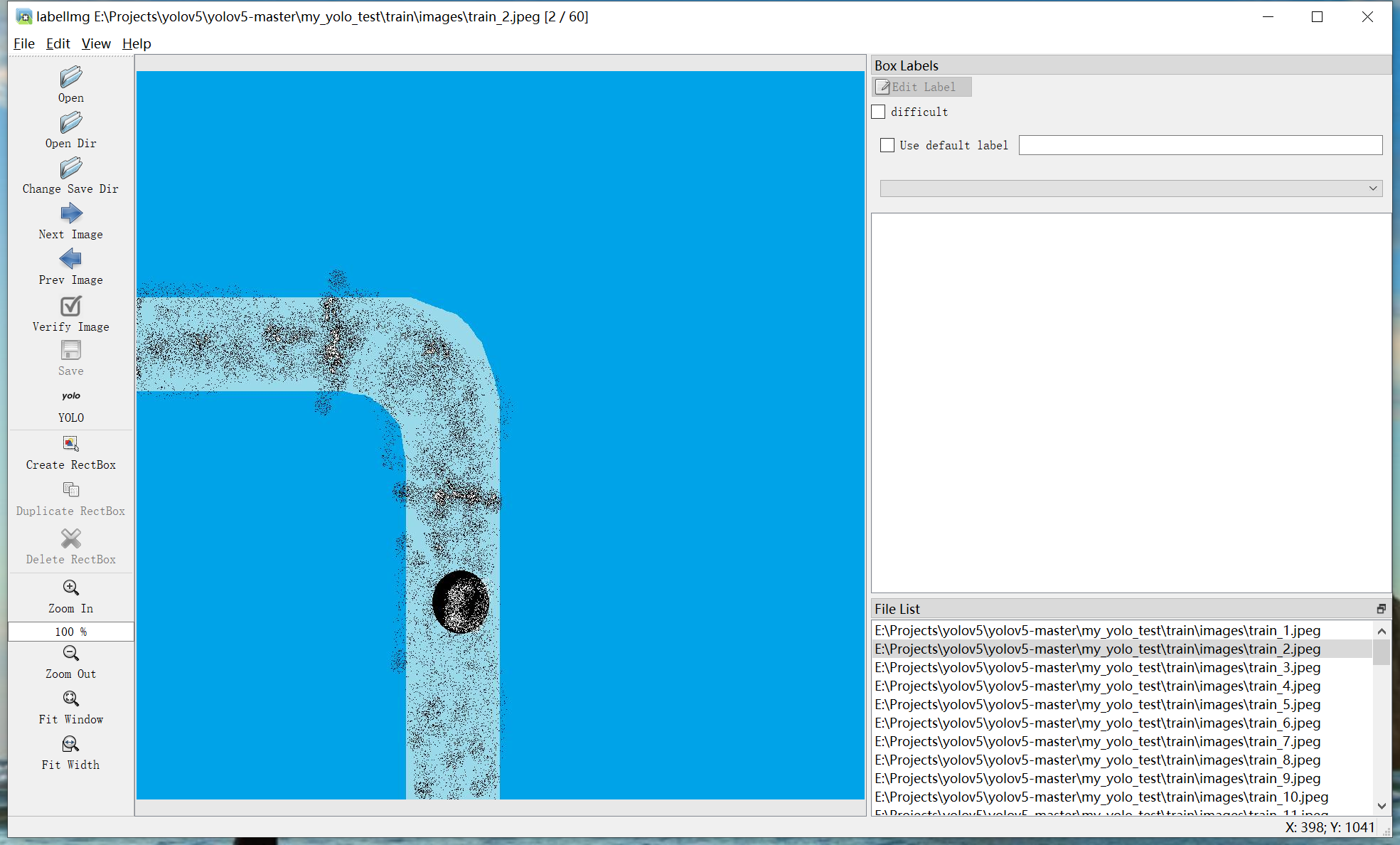
f.额外注意事项
如果已标注过,则会显示候选框,如果为相同的,则点击ok或按下回车即可,如果需要标注新的类别,则在下图红色区域内输入对应的类别名称,并点击ok来实现新建类别名称:
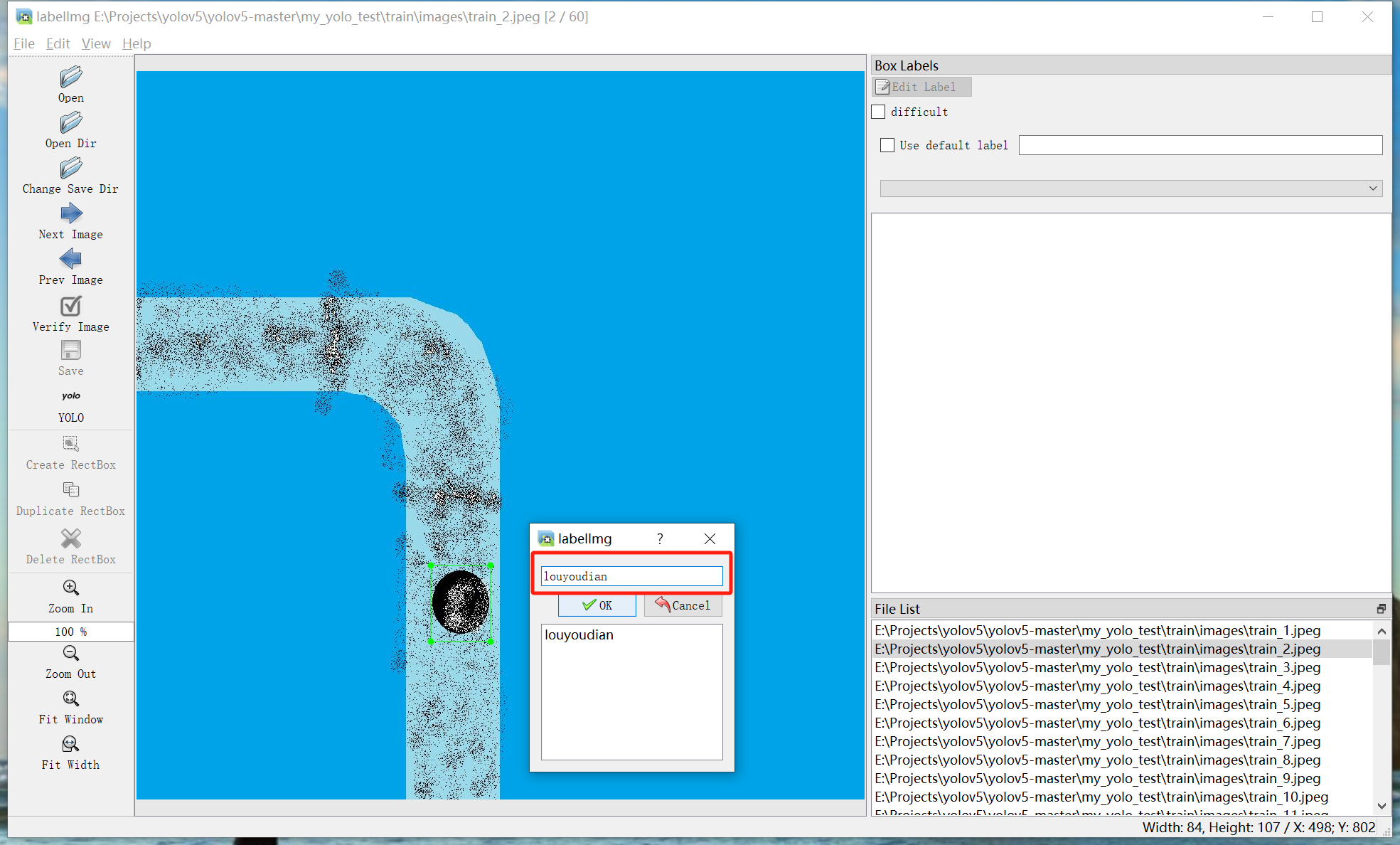
以此类推直到最后一个完成标注:
此时在对应的labels文件夹内可以看到类似的txt:
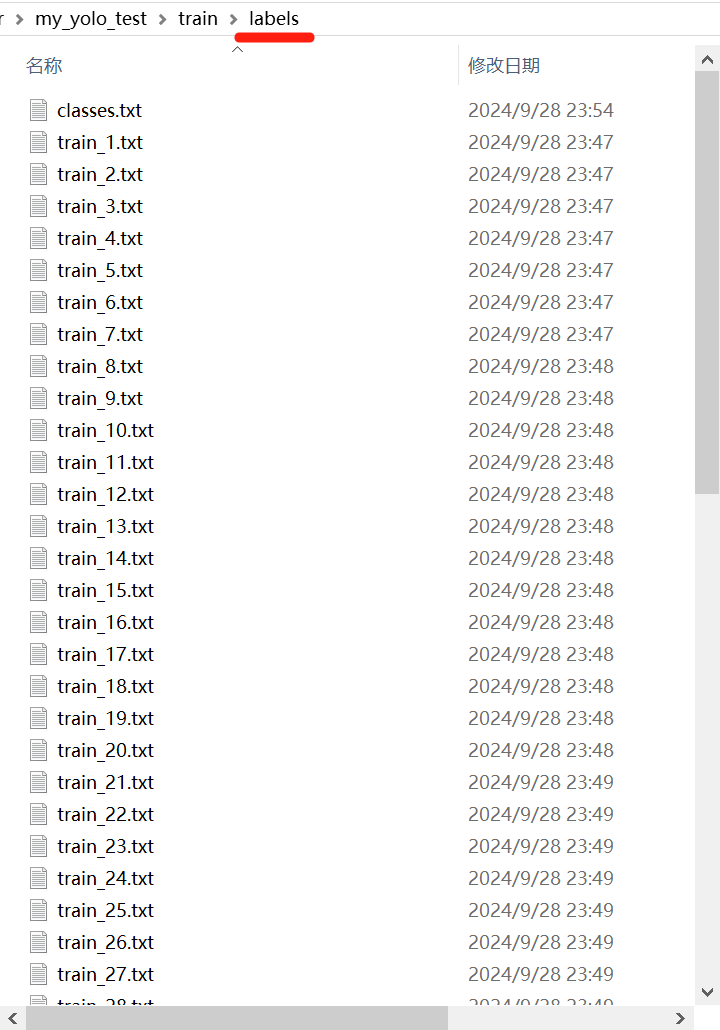
其中classes.txt内为所有的类别名称,例如“louyoudian”
其他txt和图片同名,仅后缀不同。注意此后就不要改图片和标注的文件名,如果必须修改,需要保持同步
3、将train和val全部标注完成
将train和val两个文件夹内的images文件夹内的图片全部标注完成后,即可进入下一步
十、开始训练
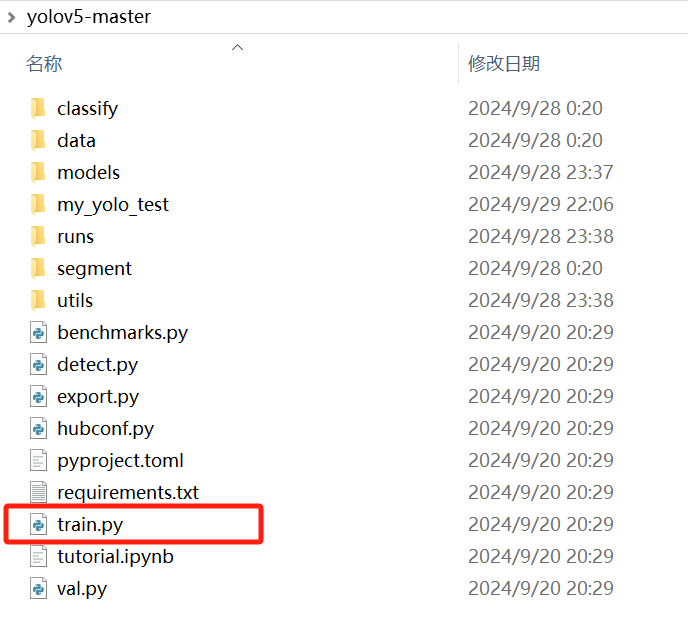
1、打开YOLOv5根目录
打开后如图所示,存在如图所示的文件结构,且存在train.py的目录,一般为根目录:
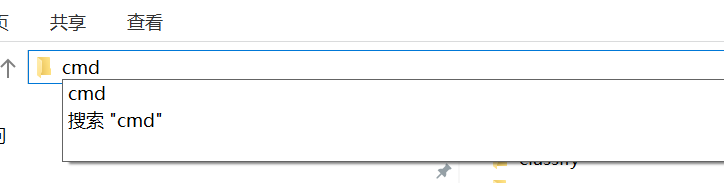
2、在当前目录打开命令行
在上方地址栏输入CMD并回车,或打开命令行后通过cd命令打开文件夹地址均可。以下按照前者举例:

3、输入训练命令
python train.py --data my_yolo_test/my_yolo_test.yaml --cfg models/yolov5n.yaml --weights models/yolov5n.pt --epochs 64 --batch-size 32 --imgsz 640 --device 0 --workers 4参数解析:
(1)--data my_yolo_test/my_yolo_test.yaml
指定了训练数据的配置文件路径为 my_yolo_test/my_yolo_test.yaml。这个配置文件可能包含了数据集的路径、类别信息等。
(2)--cfg models/yolov5n.yaml
指明了模型的配置文件路径为 models/yolov5n.yaml。该文件通常定义了模型的结构、层数、参数等信息。
(3)--weights models/yolov5n.pt
表示加载预训练权重文件的路径为 models/yolov5n.pt。预训练权重可以加速模型的收敛速度。
(4)--epochs 64
设置训练的轮数为 64。即模型将在整个数据集上进行 64 次完整的遍历。
(5)--batch-size 32
定义了每次训练时输入模型的样本数量为 32。较大的 batch size 可能需要更多的内存,但可以提高训练效率。
(6)--imgsz 640
指定输入图像的尺寸为 640x640。模型将对输入的图像进行调整大小以适应这个尺寸。
(7)--device 0
选择使用的设备编号为 0。通常表示使用第一个 GPU 进行训练。如果你的计算机有多个 GPU,可以通过调整这个编号来选择不同的 GPU。
(8)--workers 4
设置数据加载的工作线程数为 4。更多的工作线程可以加快数据加载速度,但也可能消耗更多的系统资源。
此处仅列举常见参数,其他参数请自行查阅网络资料
4、训练过程信息及结束
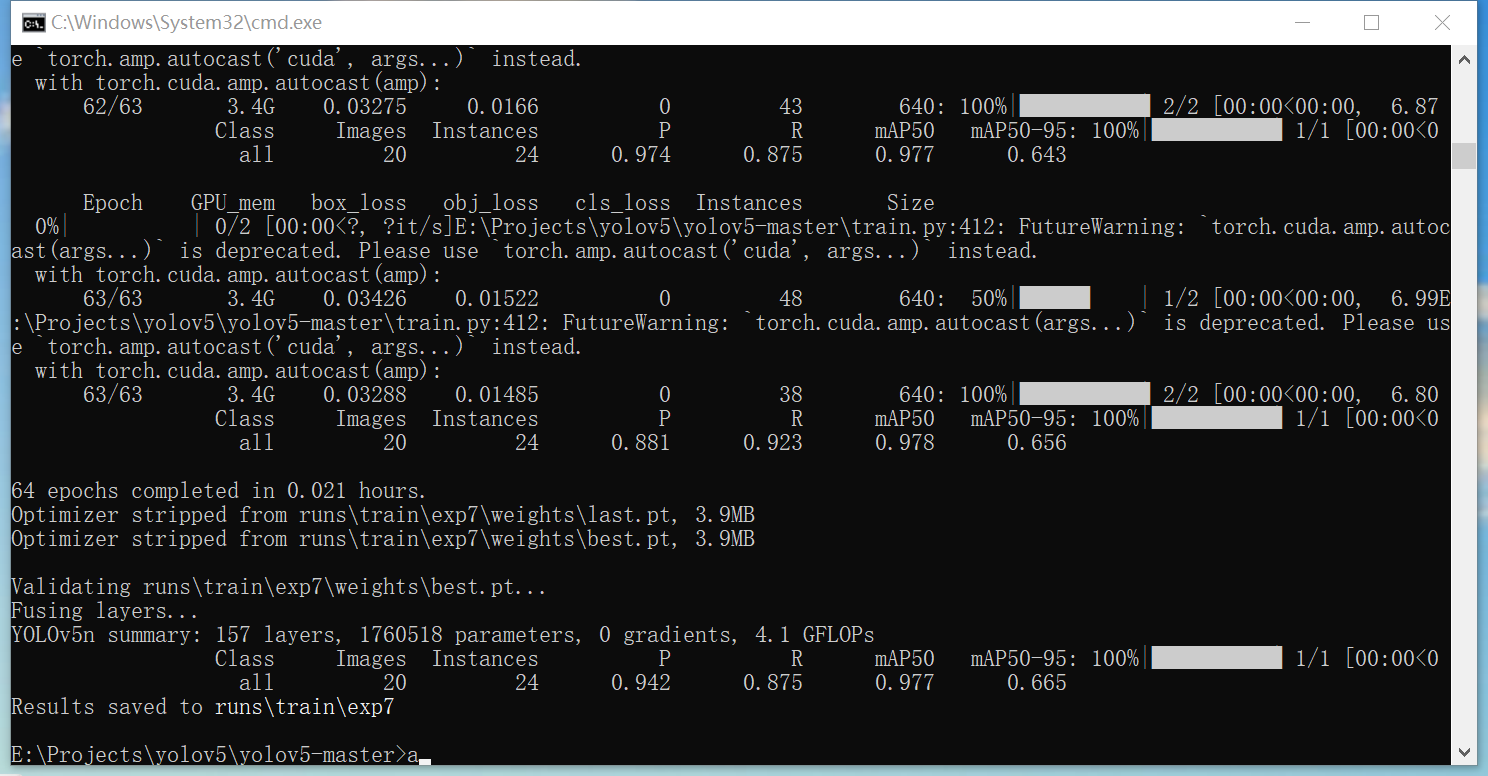
训练结束后效果如图所示,其中部分参数含义如下:
(1)mAP50:平均精度均值(mean Average Precision at IoU=0.5)。
衡量模型在 IoU 阈值为 0.5 时的检测性能。这个指标综合考虑了模型的查准率和查全率,数值越高表示模型在该阈值下对目标的检测准确性越高。例如,
mAP50 0.977表示在 IoU 为 0.5 时,模型的平均精度均值为 0.977,说明模型在这个阈值下能够较好地检测出目标,且误检和漏检较少。 (1)mAP50-95:在不同交并比(Intersection over Union,IoU)阈值从 0.5 到 0.95 之间以 0.05 为步长计算的平均精度均值。更加全面地评估模型在不同 IoU 阈值下的性能。通过在多个 IoU 阈值上计算平均精度,然后取平均值得到。这个指标能够反映模型在不同严格程度下的检测能力。数值越高,说明模型在各种 IoU 阈值下都能保持较好的检测性能,具有更强的泛化能力。例如,“mAP50-95 0.643” 表示在 IoU 从 0.5 到 0.95 的范围内,模型的平均精度均值为 0.643,虽然这个数值可能相对较低,但也表明模型在不同的检测严格程度下都有一定的检测能力。 (1)
P:精确率(Precision),表示预测为正的样本中有多少是真正的正样本。精确率关注的是模型预测为正样本的准确性。如果精确率高,说明模型在预测为正样本的情况下,大部分都是真正的正样本,误报较少。例如,“P 0.881” 表示模型的精确率为 0.881,即模型预测为正样本的结果中有 88.1% 是真正的正样本。 (1)
R:召回率(Recall),表示实际为正的样本中有多少被正确预测为正样本。召回率衡量的是模型对正样本的检出能力。如果召回率高,说明模型能够尽可能多地检测出真正的正样本,漏检较少。例如,“R 0.923” 表示模型的召回率为 0.923,即实际为正样本的对象中有 92.3% 被模型正确地预测为正样本。
一般认为mAP50-95介于0.9以上为良好,介于0.95以上为佳。一般取决于训练集和验证集的质量(包括图像内容和标签质量),部分情况下可通过调整训练轮次(主要是增加)、修改参数(如:命令中添加使用--augment参数)来实现提高效果。
最后一行:Results saved to runs/train/exp7
含义为最佳的模型保存在./runs/train/exp7目录内,后续推理将会使用这个文件夹里weights文件夹内的best.pt文件。
十一、推理(部署)
由于部署平台和方式较多,此处仅举出一个例子,调用detect.py进行简单验证,仅供测试:
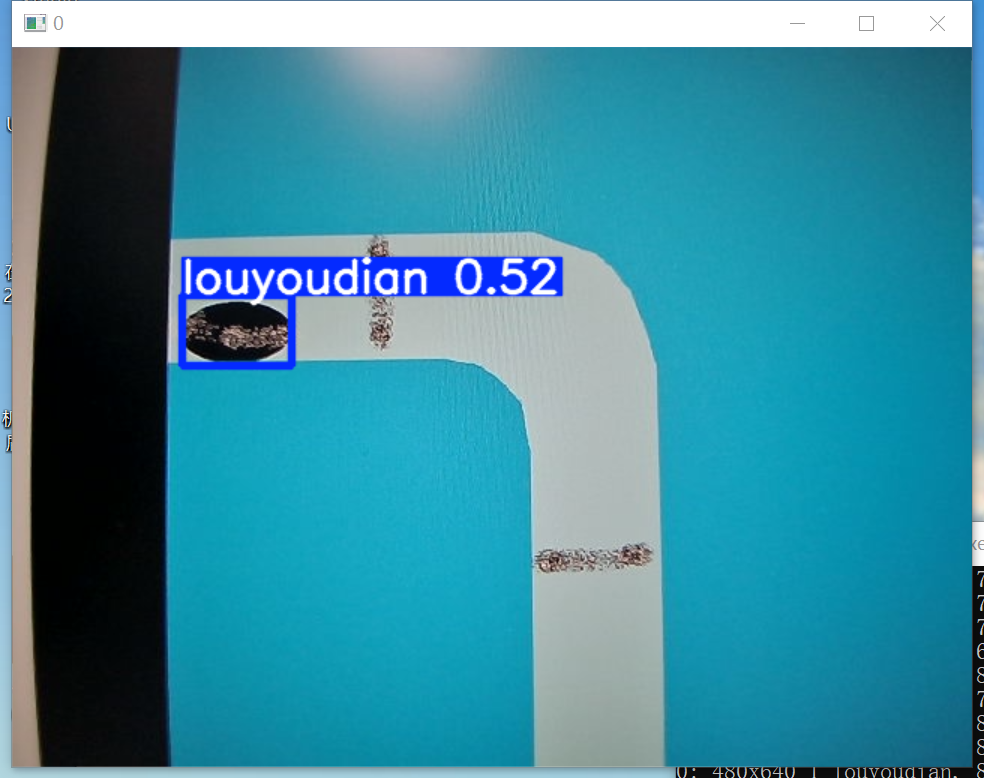
python detect.py --source 0 -- weight ./runs/train/exp7/weights/best.pt其中“--source 0 ”代表着使用0号摄像头;“-- weight ./runs/train/exp7/weights/best.pt”代表着使用“./runs/train/exp7/weights/best.pt”处的模型,这个文件地址需要根据实际情况更改,具体见上一章节最后两段。
效果如下(运行后的视频录像,会保存在./runs/detect文件夹内的文件夹里):
至此,YOLOv5教程结束
Company 机魂社 All Rights Reserved